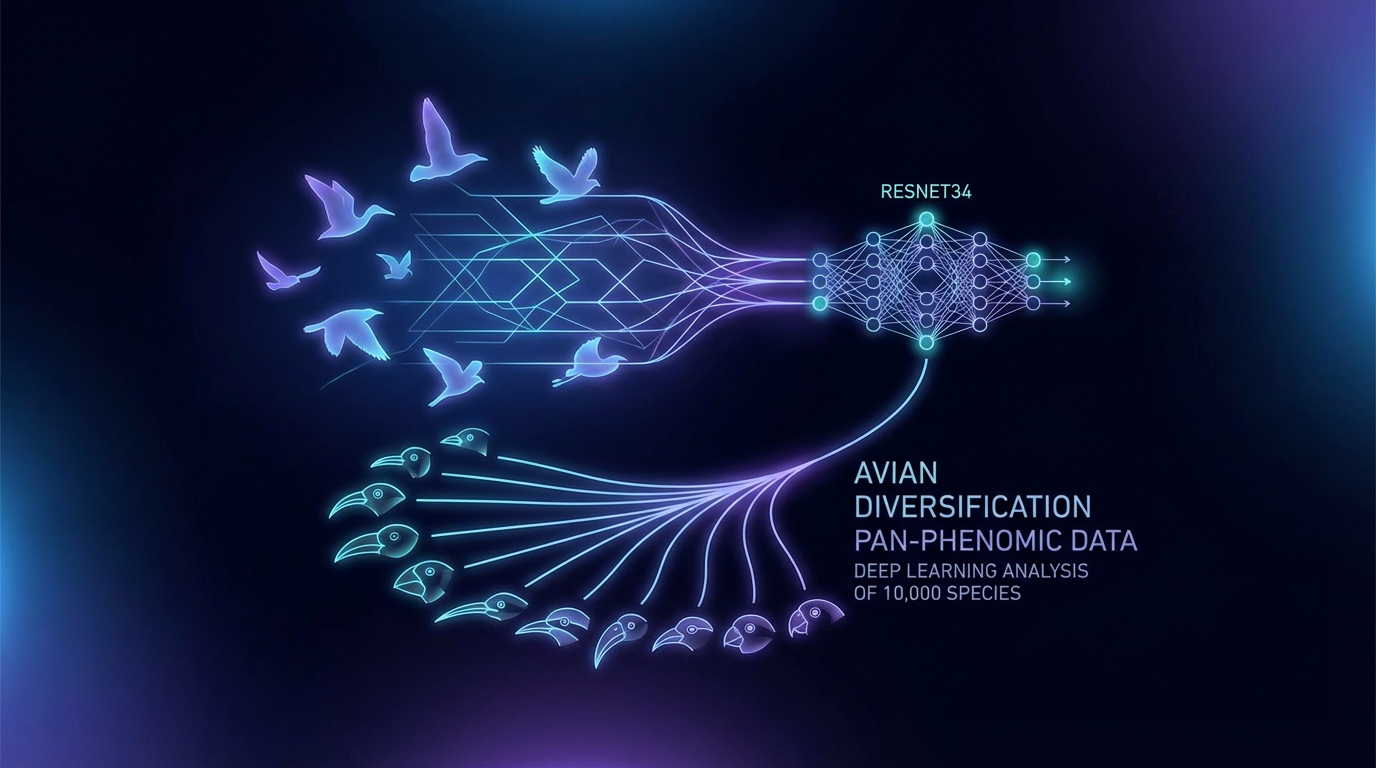
基于深度学习的全表型数据揭示了鸟类视觉差异的快速演化
最近的一项研究利用深度学习,特别是ResNet34模型,对鸟类形态演化进行了分析,识别了超过10,000种鸟类。研究表明,该模型的高维嵌入空间能够捕捉与物种丰富度相关的表型趋同和形态差异,强调了丰富度作为形态空间扩展的关键因素。后K-Pg灭绝事件的模式显示出多样性的“早期爆发”。值得注意的是,该研究还突出了模型在平面标签训练环境中形成层次结构的能力,这一发现挑战了关于卷积神经网络(CNN)依赖局部纹理的假设。
arXiv
最近的一项研究利用深度学习,特别是ResNet34模型,对鸟类形态演化进行了分析,识别了超过10,000种鸟类。研究表明,该模型的高维嵌入空间能够捕捉与物种丰富度相关的表型趋同和形态差异,强调了丰富度作为形态空间扩展的关键因素。后K-Pg灭绝事件的模式显示出多样性的“早期爆发”。值得注意的是,该研究还突出了模型在平面标签训练环境中形成层次结构的能力,这一发现挑战了关于卷积神经网络(CNN)依赖局部纹理的假设。

SymPlex推出了一种新颖的强化学习框架,能够在无需真实数据的情况下为偏微分方程(PDEs)推导出解析解。该框架采用了一种结构感知的Transformer模型——SymFormer,专门根据偏微分方程及其边界条件来优化解。这种方法能够生成可解释的解,并有效处理非光滑行为,相较于传统数值方法具有显著优势。实证测试表明,SymPlex能够准确恢复复杂的偏微分方程解,凸显了其在数学建模和工程领域的实际应用潜力。

研究人员开发了DualSpeed框架,以提高多模态大型语言模型(MLLMs)的训练效率,解决与庞大模型规模和视觉标记相关的低效问题。DualSpeed采用双模式方法:快速模式利用视觉标记裁剪(VTP)来减少视觉标记,而慢速模式则在完整序列上进行训练,以保持一致性。该方法显著加速了训练过程——LLaVA-1.5的速度提高了2.1倍,而LLaVA-NeXT则提高了4.0倍,同时保持超过99%的性能。相关代码已在GitHub上发布。

一种新的共享工业人工智能架构将虚拟双胞胎与可扩展的人工智能基础设施相结合,增强了制造业的实时决策能力。这个经过科学验证的模型优化了各类流程,使得行业能够利用人工智能进行预测性维护和提升运营效率。这一架构使工业人工智能成为现代生产环境中不可或缺的工具。

新的短片系列《在这一天……1776》以一幅感人的画面开场:一只手轻轻滑过托马斯·潘恩的《常识》标题页,突显其历史重要性。该系列旨在探讨美国独立战争期间的重要事件,为观众提供对这一时期影响深远的人物和思想的背景与洞察。

最近的ZDNET报告显示,73%的消费者正在使用人工智能聊天机器人进行产品搜索,反映出电子商务中日益增长的趋势。文章强调,随着消费者对这些技术的依赖加深,企业需要整合人工智能工具,以提升客户参与度并简化购物体验。

SpaceX宣布收购了埃隆·马斯克的人工智能初创公司xAI,这标志着其在人工智能领域的重大扩展。这一合并使SpaceX成为全球最具价值的私营公司。此次整合旨在利用xAI的技术来提升SpaceX的运营和决策流程,可能会进一步简化其在太空探索方面的雄心勃勃的项目。

美国卫生与公共服务部自三月起开始使用Palantir的人工智能工具,以提升对资助和职位描述的筛选与审核流程。该举措旨在确保符合联邦法规,并改善监督管理。预计这些人工智能工具的整合将有助于简化操作流程,减少资助管理中的错误。

PixelGen 是一个新颖的像素扩散框架,通过直接在像素空间中优化,克服了传统两阶段潜在扩散模型的局限性。它采用了两种感知损失——LPIPS 用于局部模式,DINO 用于全局语义,从而提升图像质量。PixelGen 在 ImageNet-256 上达到了 5.11 的竞争性 FID,仅经过 80 个训练周期,并且在大规模文本到图像任务中表现出色,GenEval 得分达到 0.79。这种方法省去了变分自编码器 (VAE) 和辅助阶段,提供了一种简化且高效的生成模型。完整代码可在 GitHub 上获取。

最近的一项研究提出了一种名为文本反馈强化学习(RLTF)的方法,旨在通过文本评价来优化大型语言模型的后期训练。与传统方法不同,RLTF采用了多轮强化学习,使模型能够在没有大量示范的情况下内化反馈。研究中测试了两种技术——自我蒸馏和反馈建模,结果在多个任务上始终优于现有基准,表明文本反馈能够有效显著提升模型性能。

一种基于Swin U-Net的新型门控多头变换器架构,通过整合切片间的上下文信息和并行检测头,提升了放射治疗中的自动分割效果。该模型有效降低了误报率,实现了平均Dice损失为$0.013 \pm 0.036$,而传统方法则为$0.732 \pm 0.314$。这一进展显著增强了临床环境中自动轮廓绘制的可靠性。

一项近期研究揭示了在超大规模专家混合模型(MoE)训练中实施专家并行(EP)通信所面临的挑战。该通信模型需要采用全对全的方式,这一方法受到动态变化和稀疏性的影响,增加了复杂性。研究结果表明,提高EP通信效率对于优化MoE性能至关重要,这将显著改善大规模机器学习环境中的训练时间和资源利用率。