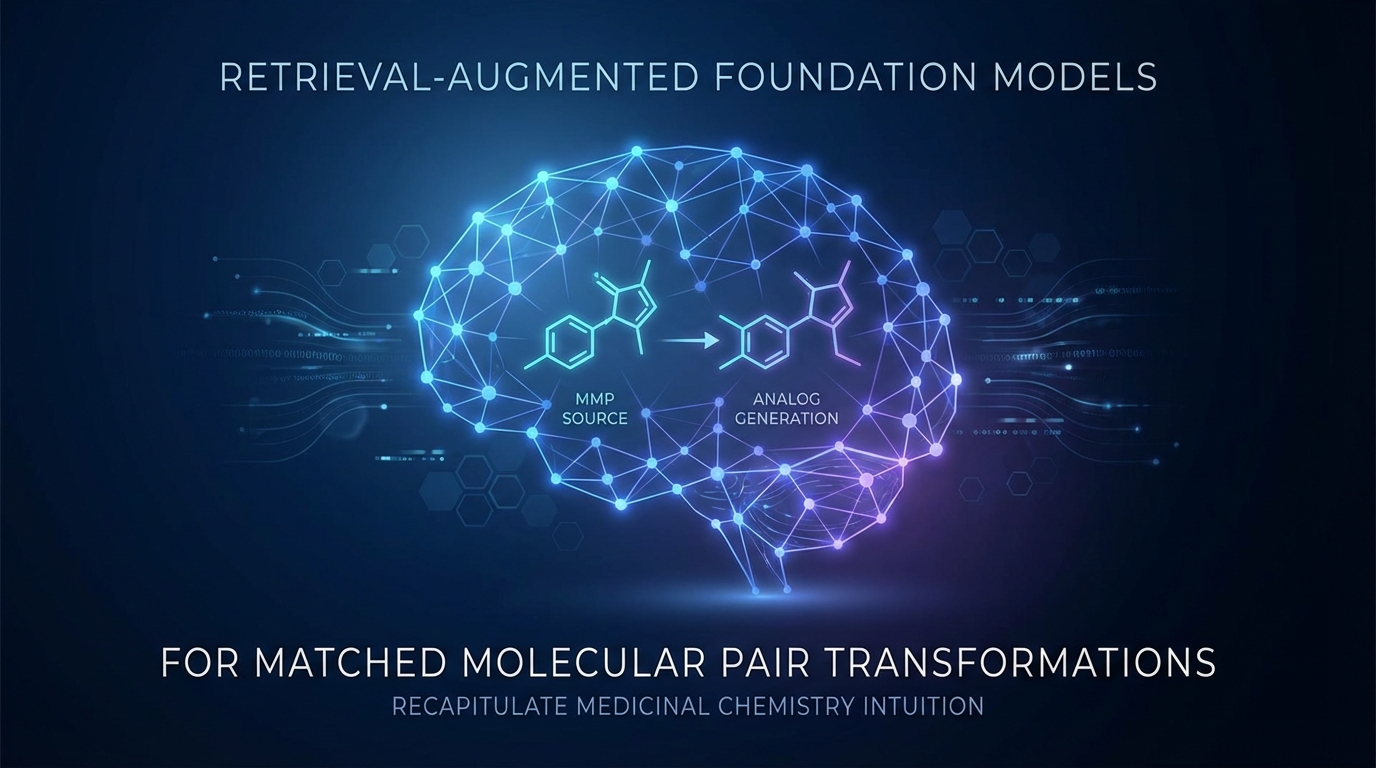
用于匹配分子对转化的检索增强基础模型以重现药物化学直觉
研究人员开发了一种新的基础模型,旨在利用匹配分子对(MMPs)生成化学类似物。该模型能够基于用户定义的转化模式生成多样化的变量,从而增强了可控性。这一方法被命名为MMPT-RAG,融入了外部参考以提高上下文的相关性。实验结果表明,所生成化合物在多样性和新颖性方面取得了显著进展,使其成为药物发现领域中药物化学的一个有价值工具。
arXiv
研究人员开发了一种新的基础模型,旨在利用匹配分子对(MMPs)生成化学类似物。该模型能够基于用户定义的转化模式生成多样化的变量,从而增强了可控性。这一方法被命名为MMPT-RAG,融入了外部参考以提高上下文的相关性。实验结果表明,所生成化合物在多样性和新颖性方面取得了显著进展,使其成为药物发现领域中药物化学的一个有价值工具。

一项新研究利用物理信息神经网络(PINN)分析太阳动力学的行为,重点研究倾斜淬火(TQ)和纬度淬火(LQ)对太阳极地场和太阳周期幅度的影响。研究人员通过调整传输参数发现,TQ抑制随着扩散率的增加而增强,而在以对流为主的条件下,LQ则占主导地位。这项研究进一步完善了TQ与LQ对偶极子形成影响之间的关系,提高了对太阳周期的预测准确性。与传统模型相比,PINN能够显著降低错误率,并更有效地捕捉非线性趋势,成为未来太阳周期预测的有力工具。

由 GitHub Copilot、LangChain 和 OpenAI 支持的代理技能框架在工业环境中对小型语言模型(SLMs)展现出了显著的潜力。一项研究对代理技能过程进行了正式定义,并评估了多种语言模型,结果显示中等规模的 SLM(参数在 120 亿到 300 亿之间)从该框架中获益良多。相比之下,较小的模型在技能选择方面则面临困难。值得注意的是,约 800 亿参数的代码专用模型在保持闭源性能的同时,提升了 GPU 的效率。这些洞见有助于在数据安全和预算受限的环境中优化代理技能的部署。

一份由乔希(Joshi)撰写的新报告,获得了环保组织的支持,揭示了许多关于环保举措的主张缺乏实质性证据。这些发现质疑了多项项目的有效性,并建议需要更为严谨的数据来支撑环保政策。这可能会对这些举措的资金支持和公众信任产生重要影响。

印度人工智能实验室Sarvam推出了一系列新的大型语言模型,旨在比现有选项更小、更高效。此举旨在通过提供开源替代方案,抢占市场份额,尤其是针对那些大型专有模型,从而提升可获取性并降低开发者和企业的成本。

近期研究揭示了大型语言模型(LLM)在保留用户信息以实现个性化互动方面存在的一个令人担忧的问题。研究表明,尽管个性化带来了诸多好处,但这些模型却有可能通过存储敏感数据来危害用户隐私。这引发了关于数据安全和用户同意在未来LLM部署中的重要问题。
印度正在举办人工智能影响峰会,汇聚全球领导者和行业专家,共同探讨人工智能的未来。会议的核心议题包括伦理人工智能的部署、监管框架,以及政府与科技公司之间的合作。与会的知名人士包括各国元首和主要人工智能企业的领袖,旨在推动国际合作并为人工智能的发展制定标准。

Python 仍然是机器学习领域的主流语言,因其用户友好的特性而广受欢迎。然而,要实现最佳的 GPU 性能,通常需要使用 C++ 来进行自定义内核开发。近期的技术进展旨在简化这一过程,使开发者能够直接在 Python 中编写高性能的 GPU 代码,从而优化工作流程并提升生产力。
随着人工智能的快速普及,开发者在优化大型语言模型(LLMs)以适应现实世界应用时面临着重大挑战。关键问题包括在管理延迟和成本的同时实现预期的性能,因为许多模型需要大量的计算资源。目前,业界正在探索解决方案,以实现效率与效果之间的平衡。
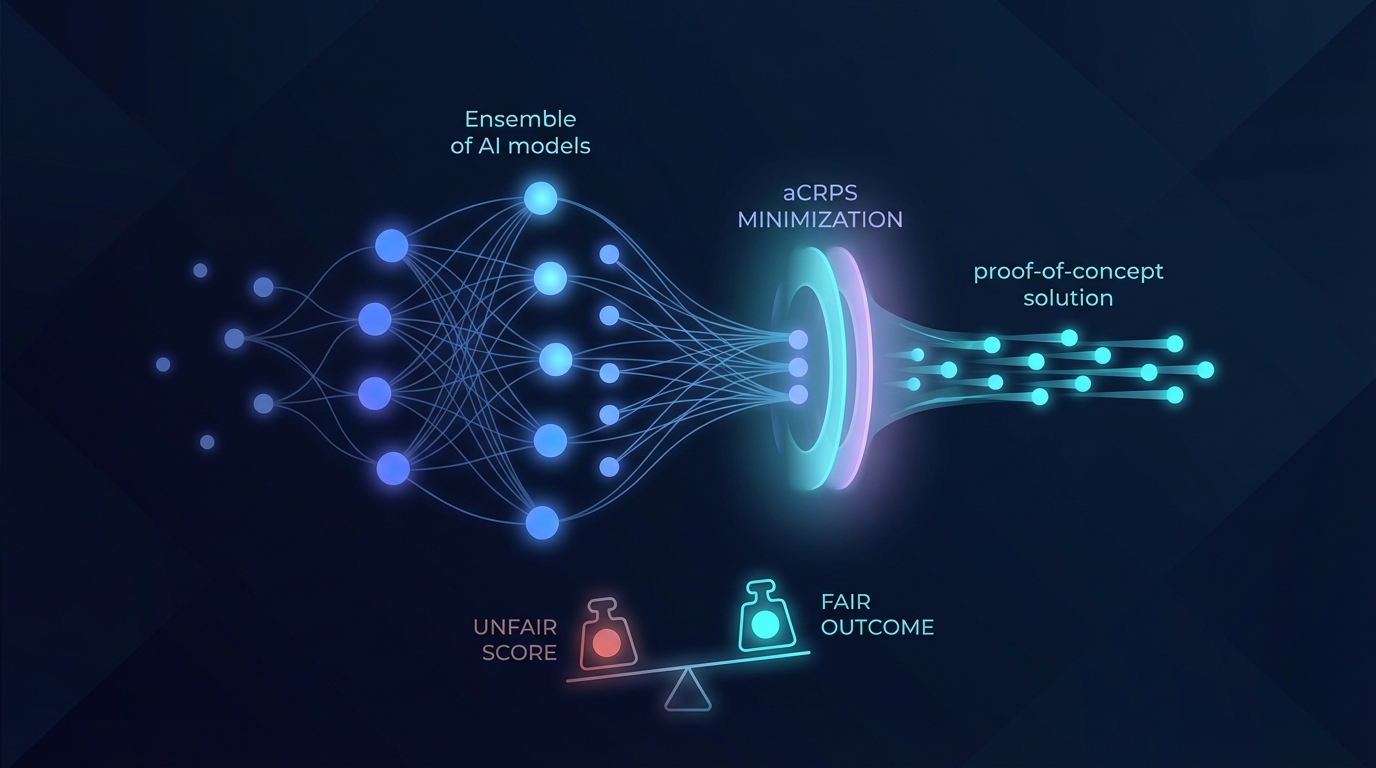
本文探讨了在训练集合预测时使用调整后的连续排名概率得分(aCRPS)所面临的挑战,尤其是在引入成员之间的结构依赖关系时。文章指出了两种存在问题的方法:线性成员校准和可能导致过度分散问题的深度学习方法。作者提出了“轨迹转换器”,对PoET框架进行了调整,以保持预测中的条件独立性。这种方法有效地减少了系统性偏差,并改善了来自欧洲中期天气预报中心(ECMWF)系统的每周平均气温预测的可靠性,无论集合规模如何(训练时为3个与9个成员;实时为9个与100个成员)。

近期研究提出了一种名为可行性导向探索(Feasibility-Guided Exploration, FGE)的方法,旨在解决深度强化学习在可达性问题上的局限性。FGE能够识别可行的初始条件,并学习出一种安全策略,在 MuJoCo 和 Kinetix 模拟器中,对于复杂场景的覆盖率比现有方法提高了超过50%。这一方法显著提高了高维控制任务的安全性。

一项新研究显示,使用大型语言模型(LLM)嵌入可以提升建筑、工程、施工和运营(AECO)行业的人工智能训练效果,帮助构建语义。针对42种建筑对象子类型进行的测试表明,该方法优于传统的一热编码,其中llama-3紧凑型嵌入实现了加权平均F1分数为0.8766。此方法增强了人工智能理解复杂语义的能力,表明在AECO相关任务中具有广泛应用的显著潜力。