深度学习后处理方法的集成规模依赖性:激励示例与概念验证解决方案
Gemini AI生成的图像
本文探讨了在训练集合预测时使用调整后的连续排名概率得分(aCRPS)所面临的挑战,尤其是在引入成员之间的结构依赖关系时。文章指出了两种存在问题的方法:线性成员校准和可能导致过度分散问题的深度学习方法。作者提出了“轨迹转换器”,对PoET框架进行了调整,以保持预测中的条件独立性。这种方法有效地减少了系统性偏差,并改善了来自欧洲中期天气预报中心(ECMWF)系统的每周平均气温预测的可靠性,无论集合规模如何(训练时为3个与9个成员;实时为9个与100个成员)。
新研究突显深度学习后处理方法对集成规模的依赖性
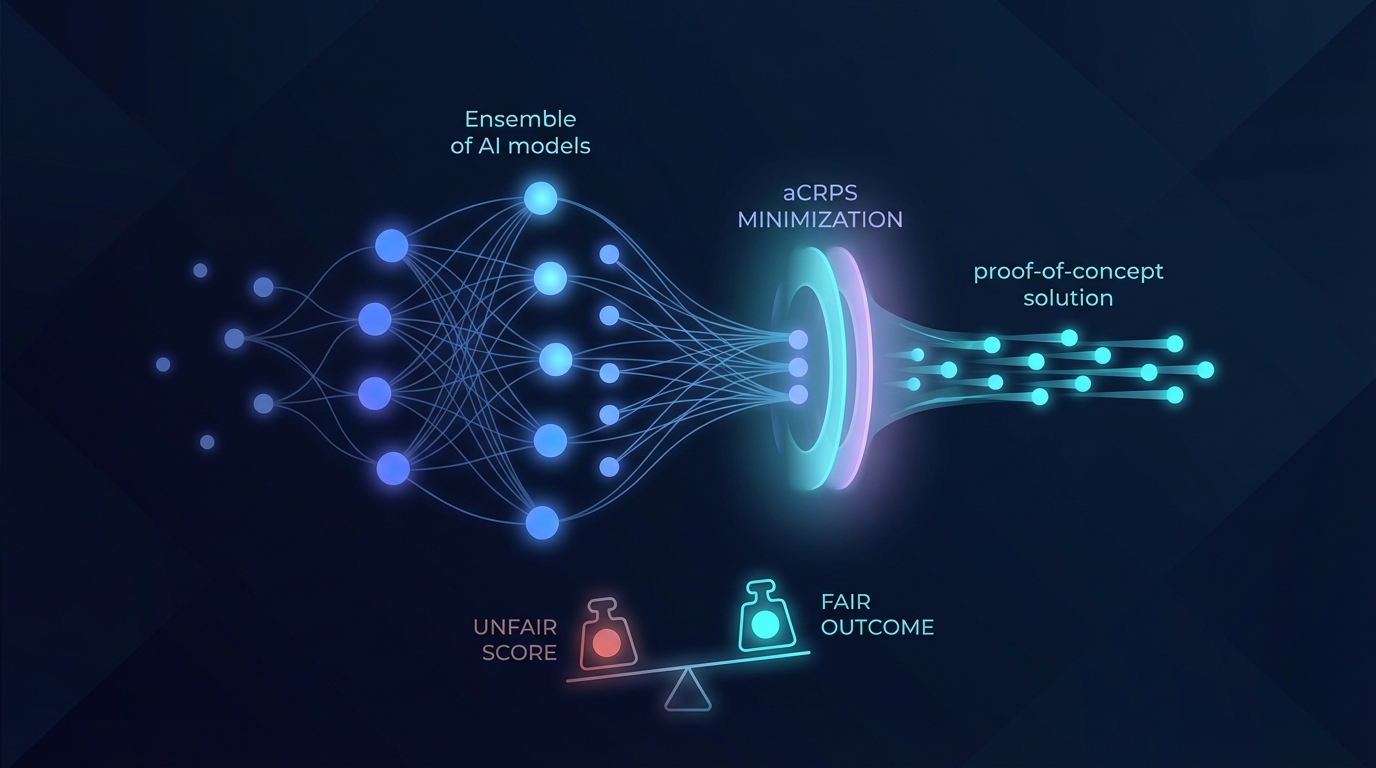
近期研究发现,某些深度学习后处理方法在集成预测中的有效性可能会受到集成规模的显著影响。该研究专注于公平评分,特别是调整后的连续排名概率评分(aCRPS),旨在在不偏向集成规模的情况下评估集成预测。
研究调查了两种旨在最小化有限集成的期望aCRPS的方法:
- 线性逐个成员校准:该方法通过对样本集成均值的共享依赖性将集成成员结合在一起。
- 使用变压器自注意力的深度学习:该技术通过在集成维度上使用自注意力机制将集成成员连接起来。
这两种方法对集成规模表现出敏感性,表明aCRPS的改善可能具有误导性,通常伴随系统性不可靠性和预测的过度离散。
轨迹变压器作为解决方案
为了解决这些问题,研究人员引入了轨迹变压器,这是对使用变压器的后处理集成(PoET)框架的概念验证适应。该方法在保持aCRPS评估所需的条件独立性的同时,跨时间段采用自注意力。
应用于来自ECMWF季节性预测系统的每周平均2米温度预测,轨迹变压器有效减少了系统模型偏差,并改善了预测的可靠性,无论训练中使用的集成规模如何。
相关主题:
深度学习后处理方法公平评分aCRPS集成规模
📰 原始来源: https://arxiv.org/abs/2602.15830v1
所有权利和署名均属于原出版商。