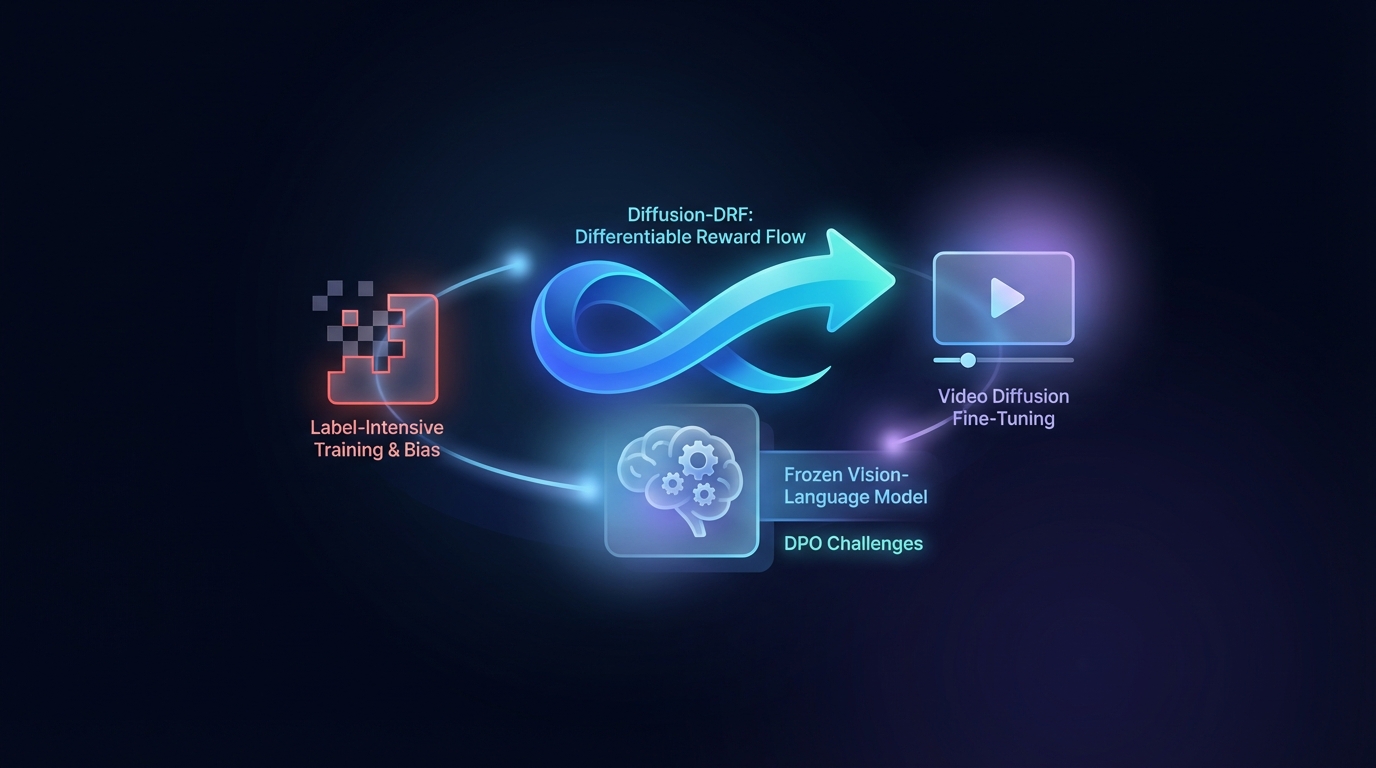
Diffusion-DRF: Flux de Recompensa Diferenciável para Ajuste Fino de Difusão de Vídeo
A Otimização de Preferências Diretas (DPO) aprimora a geração de Texto para Vídeo, mas enfrenta desafios relacionados ao treinamento intensivo em rótulos e viés. O método proposto, Diffusion-DRF, utiliza um Modelo de Visão-Linguagem congelado como um crítico diferenciável, permitindo a retropropagação eficiente do feedback por meio de modelos de difusão de vídeo. Essa abordagem melhora a qualidade do vídeo e o alinhamento semântico, ao mesmo tempo em que reduz problemas de manipulação de recompensas, sendo adaptável a outras tarefas baseadas em difusão sem a necessidade de modelos de recompensa adicionais.
arXiv