Diffusion-DRF: Flux de Recompensa Diferenciável para Ajuste Fino de Difusão de Vídeo
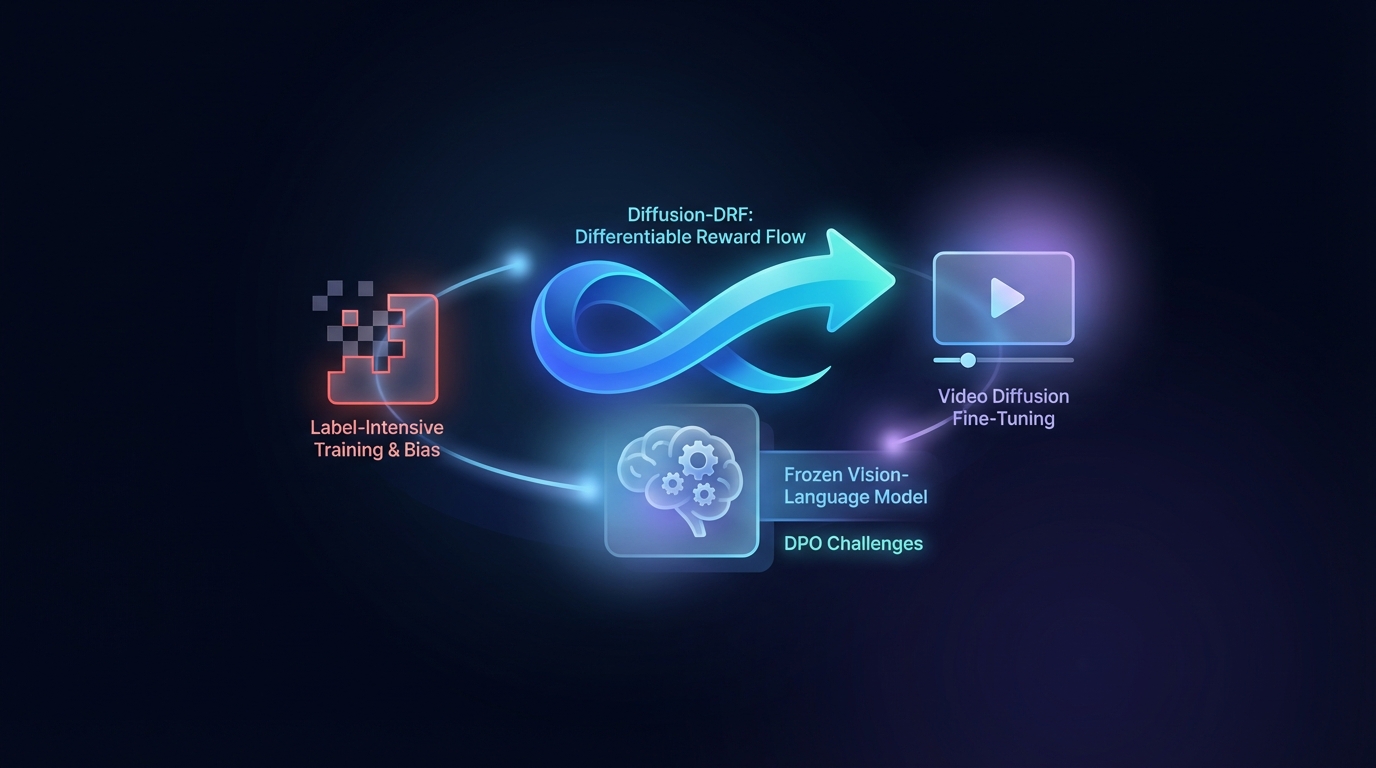
Imagem gerada por Gemini AI
A Otimização de Preferências Diretas (DPO) aprimora a geração de Texto para Vídeo, mas enfrenta desafios relacionados ao treinamento intensivo em rótulos e viés. O método proposto, Diffusion-DRF, utiliza um Modelo de Visão-Linguagem congelado como um crítico diferenciável, permitindo a retropropagação eficiente do feedback por meio de modelos de difusão de vídeo. Essa abordagem melhora a qualidade do vídeo e o alinhamento semântico, ao mesmo tempo em que reduz problemas de manipulação de recompensas, sendo adaptável a outras tarefas baseadas em difusão sem a necessidade de modelos de recompensa adicionais.
Diffusion-DRF: Um Avanço na Ajuste Fino de Difusão de Vídeo
Pesquisadores introduziram o Diffusion-DRF, um método inovador para o ajuste fino de modelos de difusão de vídeo que melhora a qualidade do vídeo e o alinhamento semântico. Esta abordagem aproveita um Modelo de Visão-Linguagem (VLM) congelado como um crítico sem treinamento, marcando um avanço significativo em relação aos métodos existentes.
O Diffusion-DRF aborda desafios comuns na geração tradicional de Texto-para-Vídeo (T2V) ao integrar feedback do VLM diretamente na cadeia de desnoising de difusão. Este método permite a retropropagação do feedback do VLM, convertendo respostas em nível de logit em gradientes conscientes de tokens que facilitam a otimização, mitigando efetivamente problemas relacionados à manipulação de recompensas e ao colapso do modelo.
Notavelmente, o Diffusion-DRF é agnóstico em relação ao modelo, aplicável a várias tarefas generativas baseadas em difusão além da geração T2V, posicionando-o como uma ferramenta valiosa para futuros avanços na geração de vídeo.
Tópicos relacionados:
📰 Fonte original: https://arxiv.org/abs/2601.04153v1
Todos os direitos e créditos pertencem ao editor original.