Conjunto de Dados de Relatórios de Radiologia Sintética Multi-RADS e Benchmarking Comparativo de 41 Modelos de Linguagem Abertos e Proprietários
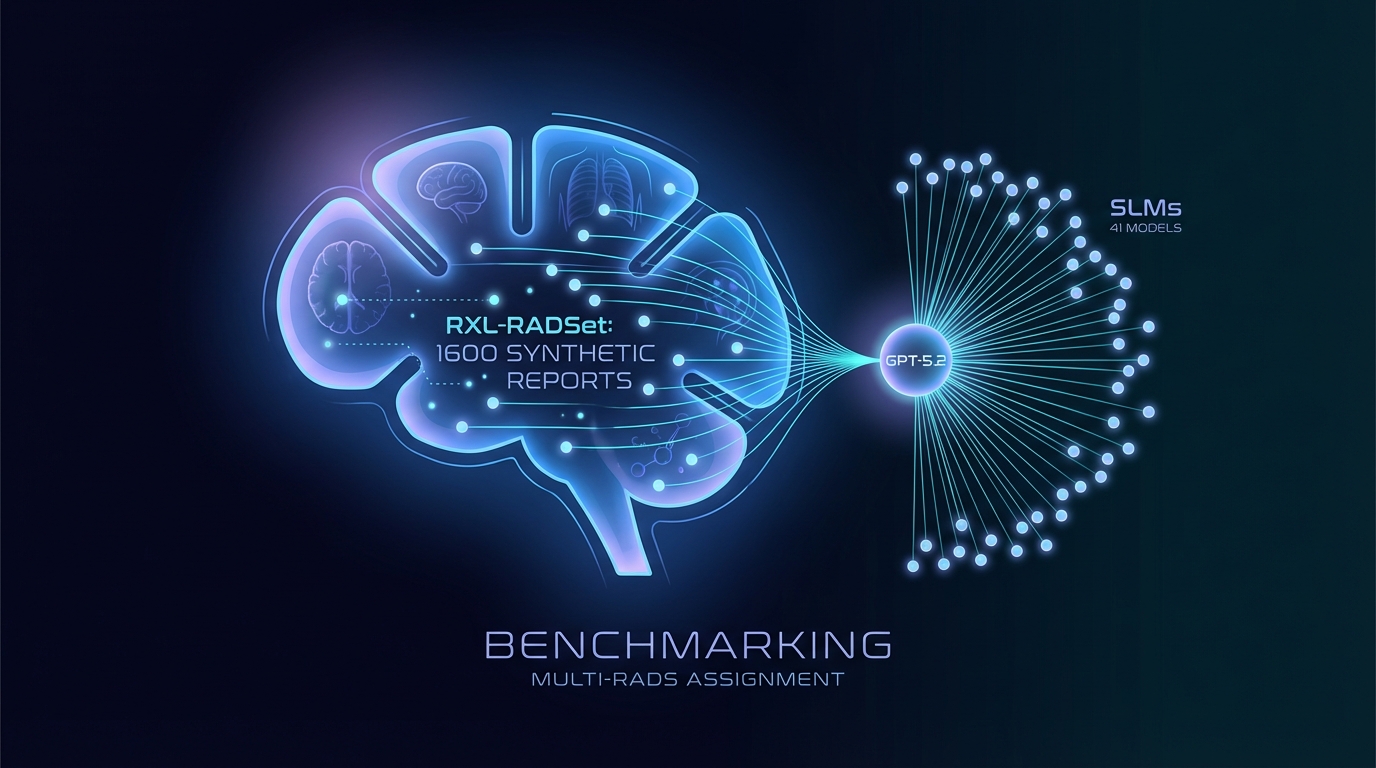
Imagem gerada por Gemini AI
Pesquisadores desenvolveram o RXL-RADSet, um conjunto de dados com 1.600 relatórios de radiologia sintéticos, com o objetivo de aprimorar a atribuição automatizada de RADS. O estudo comparou 41 pequenos modelos de linguagem (SLMs) com o GPT-5.2 em termos de precisão e validade. O GPT-5.2 alcançou uma validade de 99,8% e uma precisão de 81,1%, superando os SLMs, que apresentaram 96,8% de validade e 61,1% de precisão. O desempenho melhorou com o aumento do tamanho do modelo e o uso de prompts guiados, mas ainda há desafios a serem enfrentados em relação a estruturas RADS mais complexas.
Conjunto de Dados Multi-RADS Lançado para Modelos de Linguagem em Radiologia
Um novo conjunto de dados destinado a melhorar a comunicação de riscos em radiologia foi lançado, apresentando um benchmark de relatórios de radiologia sintéticos em múltiplos Sistemas de Comunicação e Dados (RADS). Conhecido como RXL-RADSet, ele inclui 1.600 relatórios sintéticos verificados por radiologistas, projetados para avaliar o desempenho de vários modelos de linguagem na atribuição automatizada de RADS.
Avaliação de Desempenho de Modelos de Linguagem
O estudo avaliou 41 modelos de linguagem pequenos quantizados (SLMs) com tamanhos de parâmetros variando de 0,135 a 32 bilhões, juntamente com o modelo proprietário GPT-5.2. As principais métricas para avaliação foram a validade e a precisão das atribuições de RADS.
Os resultados indicaram que o GPT-5.2 alcançou 99,8% de validade e 81,1% de precisão em 1.600 previsões. Em contraste, os SLMs agrupados produziram uma validade de 96,8% e uma precisão de 61,1% a partir de um total de 65.600 previsões. Os SLMs de melhor desempenho na faixa de parâmetros de 20 a 32 bilhões se aproximaram de 99% de validade e alcançaram taxas de precisão entre 70% e 80%.
A análise revelou uma tendência em que o desempenho melhorou com o tamanho do modelo, notando-se particularmente um ponto de inflexão entre modelos com menos de 1 bilhão de parâmetros e aqueles com 10 bilhões ou mais. No entanto, a complexidade dos frameworks RADS impactou significativamente o desempenho, com uma complexidade maior levando a desafios de classificação em vez de saídas inválidas.
O uso de prompting orientado melhorou tanto a validade quanto a precisão, com pontuações de validade alcançando 99,2% em comparação com 96,7% com prompting zero-shot.
Tópicos relacionados:
📰 Fonte original: https://arxiv.org/abs/2601.03232v1
Todos os direitos e créditos pertencem ao editor original.