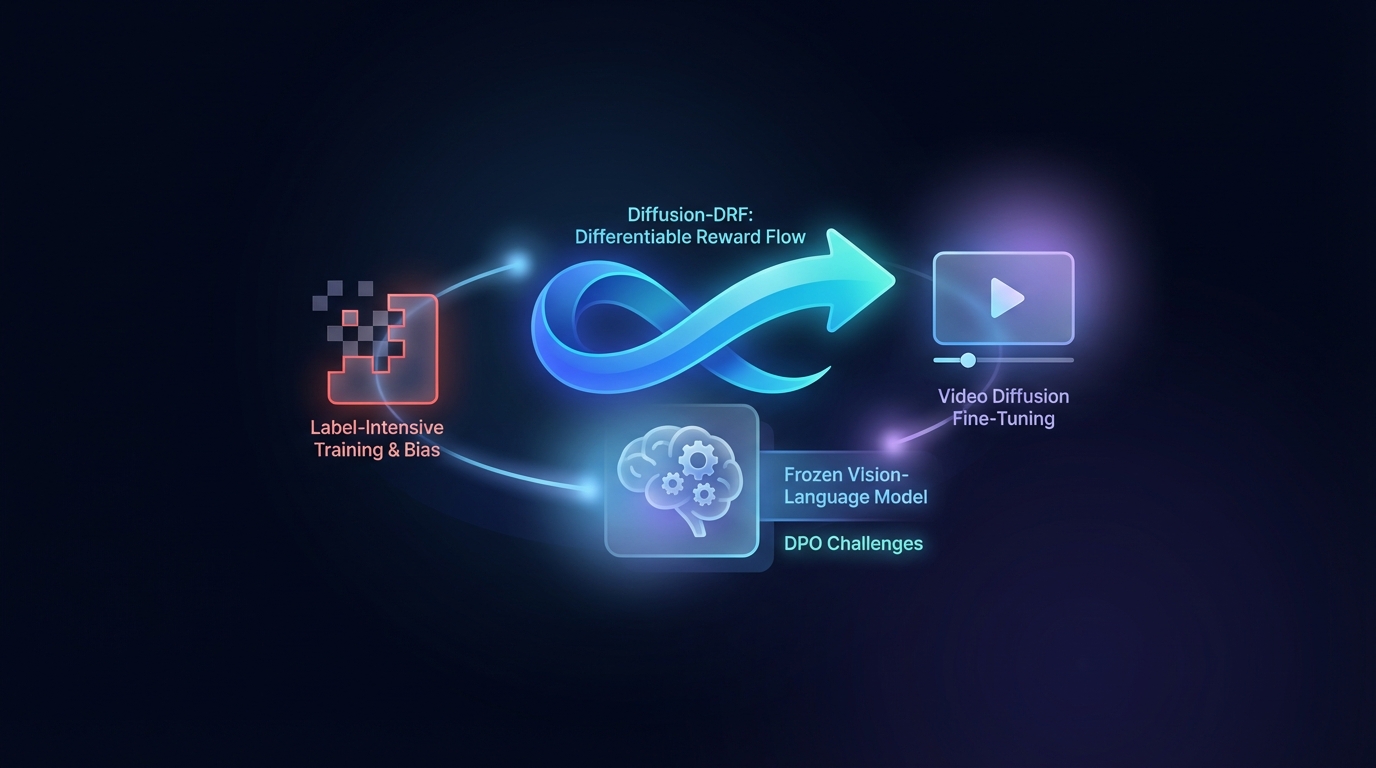
Diffusion-DRF: Flujo de Recompensa Diferenciable para el Ajuste de Difusión en Video
La Optimización de Preferencias Directas (DPO) mejora la generación de Texto a Video, pero enfrenta desafíos relacionados con el entrenamiento intensivo en etiquetas y sesgos. El método propuesto, Diffusion-DRF, utiliza un Modelo de Visión-Lenguaje congelado como crítico diferenciable, lo que permite una retropropagación eficiente de los comentarios a través de modelos de difusión de video. Este enfoque mejora la calidad del video y la alineación semántica, al mismo tiempo que reduce los problemas de manipulación de recompensas, siendo además adaptable a otras tareas basadas en difusión sin necesidad de modelos de recompensa adicionales.
arXiv