Diffusion-DRF: Flujo de Recompensa Diferenciable para el Ajuste de Difusión en Video
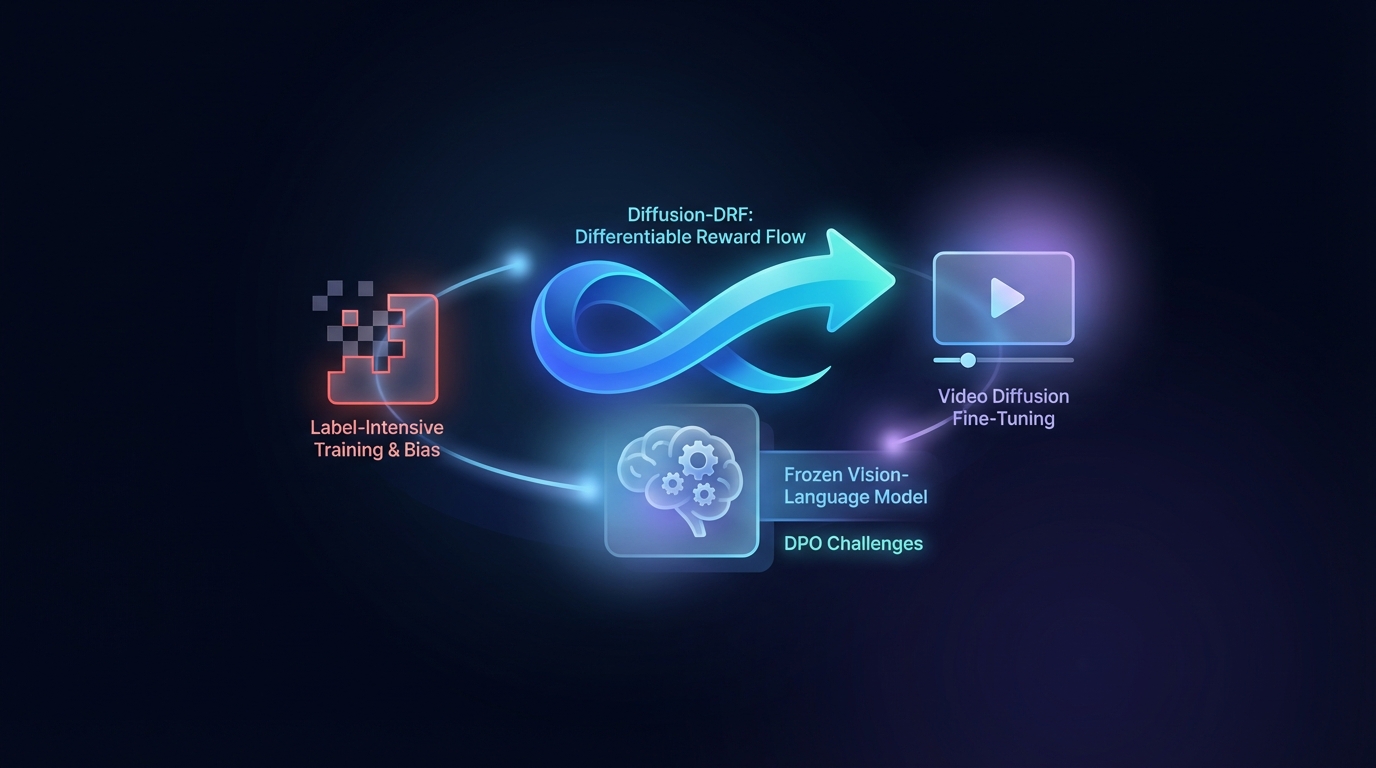
Imagen generada por Gemini AI
La Optimización de Preferencias Directas (DPO) mejora la generación de Texto a Video, pero enfrenta desafíos relacionados con el entrenamiento intensivo en etiquetas y sesgos. El método propuesto, Diffusion-DRF, utiliza un Modelo de Visión-Lenguaje congelado como crítico diferenciable, lo que permite una retropropagación eficiente de los comentarios a través de modelos de difusión de video. Este enfoque mejora la calidad del video y la alineación semántica, al mismo tiempo que reduce los problemas de manipulación de recompensas, siendo además adaptable a otras tareas basadas en difusión sin necesidad de modelos de recompensa adicionales.
Diffusion-DRF: Un Avance en el Ajuste Fino de Difusión de Video
Investigadores han introducido Diffusion-DRF, un método novedoso para el ajuste fino de modelos de difusión de video que mejora la calidad del video y la alineación semántica. Este enfoque aprovecha un Modelo de Visión-Lenguaje (VLM) congelado como un crítico sin necesidad de entrenamiento, marcando un avance significativo sobre los métodos existentes.
Diffusion-DRF aborda los desafíos comunes en la generación tradicional de Texto-a-Video (T2V) al integrar la retroalimentación del VLM directamente en la cadena de eliminación de ruido de la difusión. Este método permite la retropropagación de la retroalimentación del VLM, convirtiendo las respuestas a nivel de logit en gradientes conscientes de tokens que facilitan la optimización, mitigando efectivamente problemas relacionados con el hacking de recompensas y el colapso del modelo.
Notablemente, Diffusion-DRF es agnóstico al modelo, aplicable a diversas tareas generativas basadas en difusión más allá de la generación de T2V, posicionándolo como una herramienta valiosa para futuros avances en la generación de video.
Temas relacionados:
📰 Fuente original: https://arxiv.org/abs/2601.04153v1
Todos los derechos y créditos pertenecen al editor original.