Conjunto de datos de informes radiológicos sintéticos Multi-RADS y evaluación comparativa de 41 modelos de lenguaje de código abierto y propietarios.
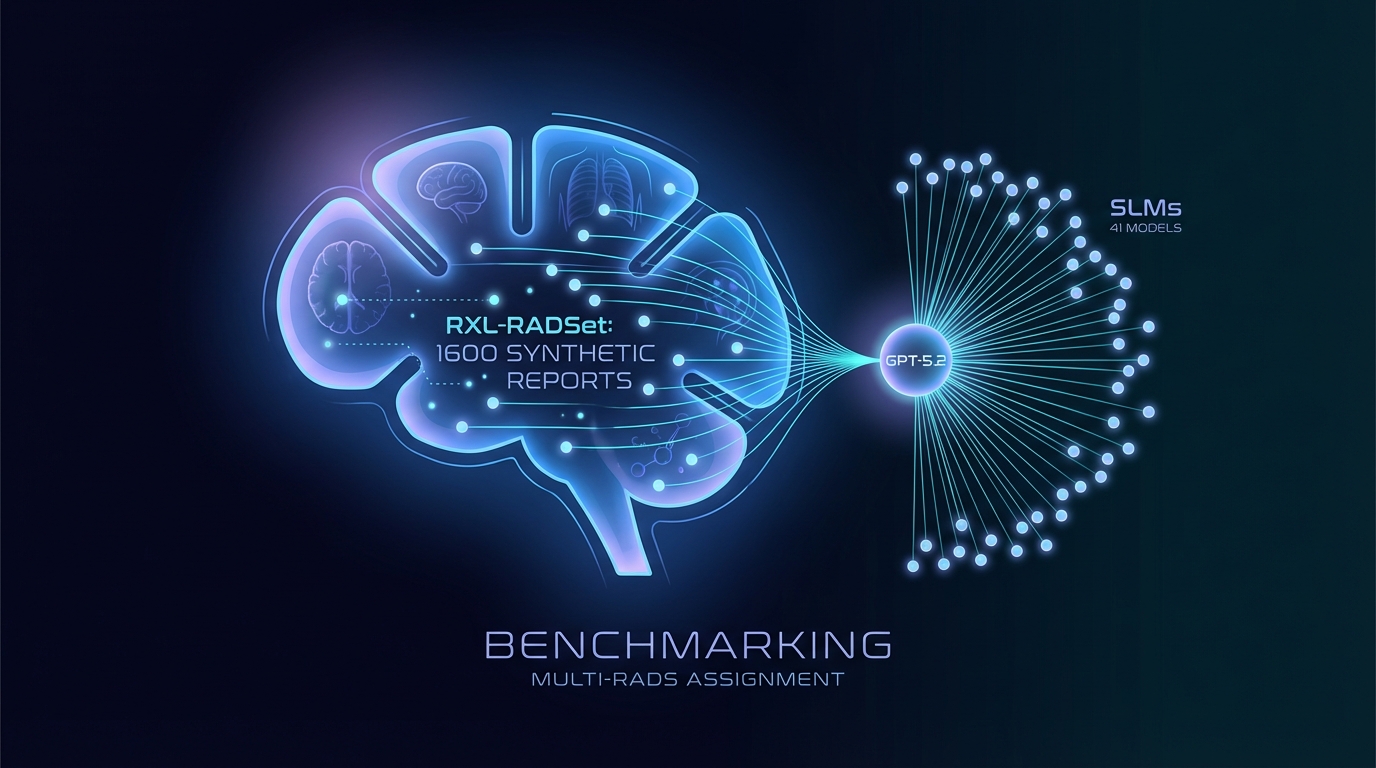
Imagen generada por Gemini AI
Investigadores han desarrollado RXL-RADSet, un conjunto de datos que consta de 1,600 informes de radiología sintéticos, con el objetivo de mejorar la asignación automatizada de RADS. Este benchmark compara 41 pequeños modelos de lenguaje (SLMs) con GPT-5.2 en términos de precisión y validez. GPT-5.2 alcanzó una validez del 99.8% y una precisión del 81.1%, superando a los SLMs, que mostraron una validez del 96.8% y una precisión del 61.1%. El rendimiento mejoró con el tamaño del modelo y las indicaciones guiadas, aunque persisten desafíos para los marcos RADS más complejos.
Conjunto de Datos Multi-RADS para Benchmarking Lanzado para Modelos de Lenguaje en Radiología
Se ha lanzado un nuevo conjunto de datos destinado a mejorar la comunicación del riesgo en radiología, que presenta un benchmark de informes de radiología sintéticos a través de múltiples Sistemas de Reporte y Datos (RADS). Conocido como RXL-RADSet, incluye 1,600 informes sintéticos verificados por radiólogos, diseñados para evaluar el rendimiento de varios modelos de lenguaje en la asignación automatizada de RADS.
Evaluación del Rendimiento de Modelos de Lenguaje
El estudio evaluó 41 modelos de lenguaje pequeños cuantizados (SLMs) con tamaños de parámetros que varían de 0.135 a 32 mil millones, junto con el modelo propietario GPT-5.2. Las métricas principales para la evaluación fueron la validez y precisión de las asignaciones de RADS.
Los resultados indicaron que GPT-5.2 alcanzó una validez del 99.8% y una precisión del 81.1% en 1,600 predicciones. En contraste, los SLMs agrupados produjeron una validez del 96.8% y una precisión del 61.1% de un total de 65,600 predicciones. Los SLMs con mejor rendimiento en el rango de 20 a 32 mil millones de parámetros se acercaron al 99% de validez y lograron tasas de precisión de entre el 70% y el 80%.
El análisis reveló una tendencia en la que el rendimiento mejoraba con el tamaño del modelo, observando particularmente un punto de inflexión entre los modelos con menos de 1 mil millones de parámetros y aquellos con 10 mil millones o más. Sin embargo, la complejidad de los marcos de RADS impactó significativamente el rendimiento, con una mayor complejidad llevando a desafíos de clasificación en lugar de resultados inválidos.
La orientación guiada mejoró tanto la validez como la precisión, con puntuaciones de validez alcanzando el 99.2% en comparación con el 96.7% con la orientación de cero disparos.
Temas relacionados:
📰 Fuente original: https://arxiv.org/abs/2601.03232v1
Todos los derechos y créditos pertenecen al editor original.