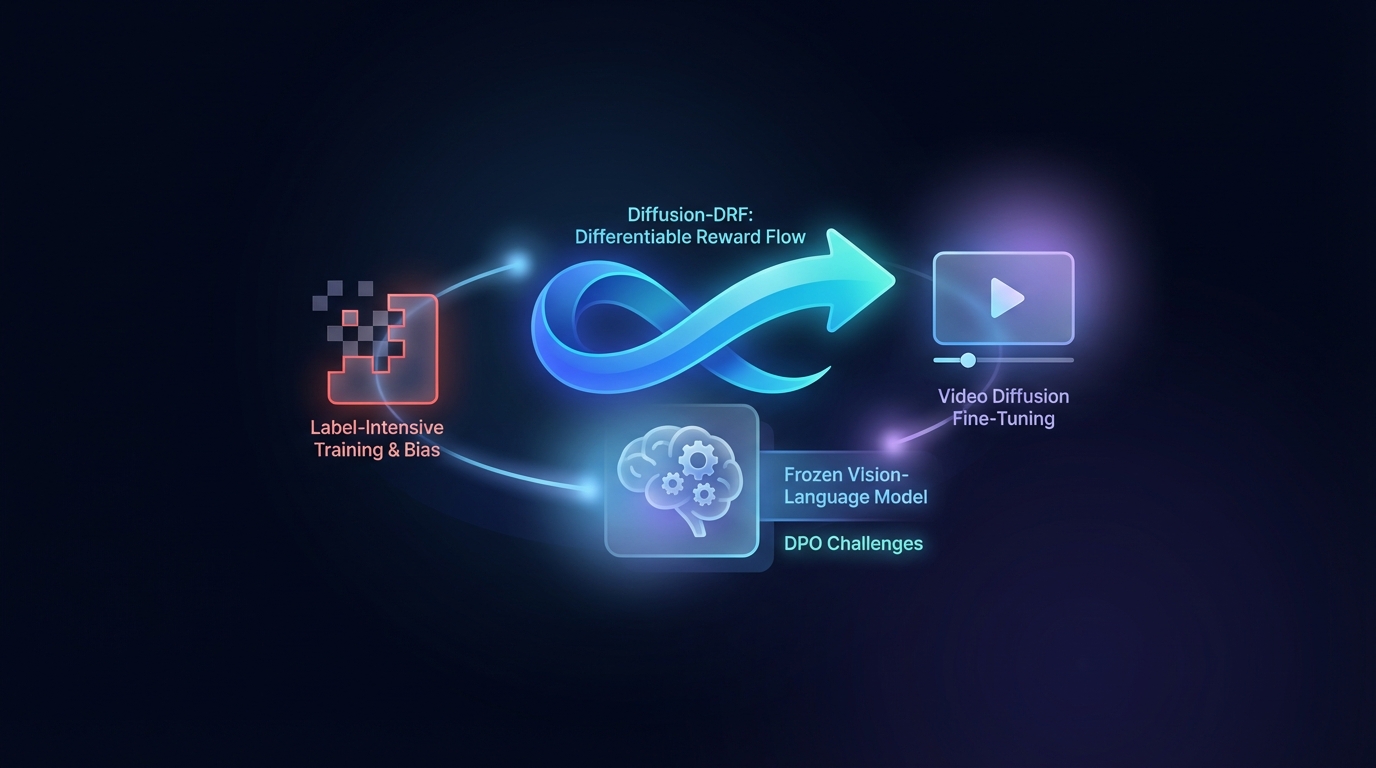
Diffusion-DRF: Differenzierbarer Belohnungsfluss für das Feintuning von Video-Diffusion
Die direkte Präferenzoptimierung (DPO) verbessert die Text-zu-Video-Generierung, sieht sich jedoch Herausforderungen durch den hohen Aufwand für die Beschriftung und durch Verzerrungen gegenüber. Die vorgeschlagene Methode Diffusion-DRF nutzt ein gefrorenes Vision-Language-Modell als differenzierbaren Kritiker, was eine effiziente Rückpropagation von Feedback durch Videodiffusionsmodelle ermöglicht. Dieser Ansatz steigert die Videoqualität und die semantische Übereinstimmung, während er gleichzeitig Probleme mit der Belohnungsmanipulation reduziert. Zudem ist er anpassungsfähig für andere auf Diffusion basierende Aufgaben, ohne dass zusätzliche Belohnungsmodelle erforderlich sind.
arXiv