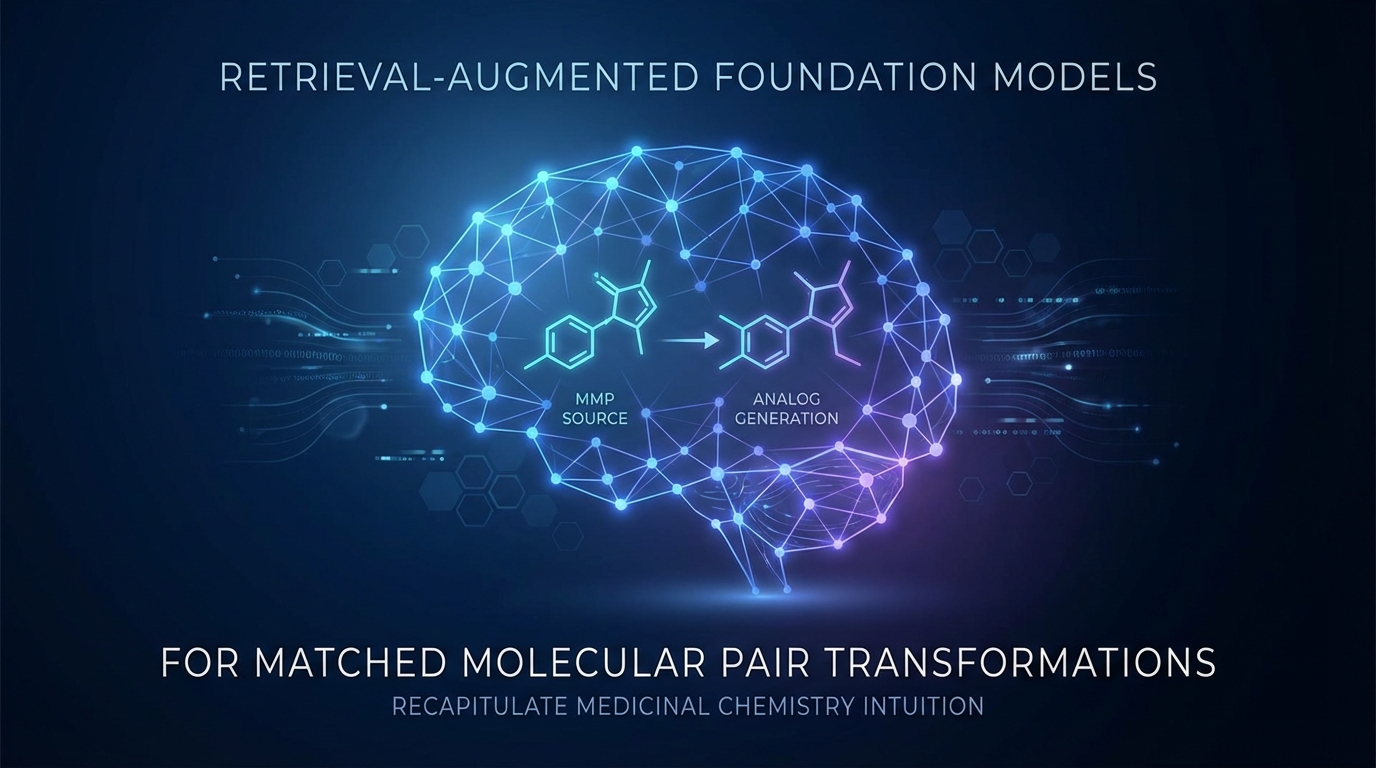
Wiedererlangungs-unterstützte Grundmodelle für angepasste molekulare Paartransformationen zur Rekapitulation der Intuition der Arzneimittelsynthese
Forscher haben ein neues Grundmodell zur Generierung chemischer Analoga entwickelt, das auf passenden Molekülpaaren (MMPs) basiert. Dieses Modell ermöglicht die vielfältige Erzeugung von Variablen, die auf benutzerdefinierten Transformationsmustern beruhen, und verbessert damit die Steuerbarkeit. Die Methode mit dem Namen MMPT-RAG integriert externe Referenzen, um die kontextuelle Relevanz zu steigern. Experimente zeigen bedeutende Fortschritte in der Diversität und Neuheit der erzeugten Verbindungen, was es zu einem wertvollen Werkzeug für die medizinische Chemie in der praktischen Arzneimittelentdeckung macht.
arXiv