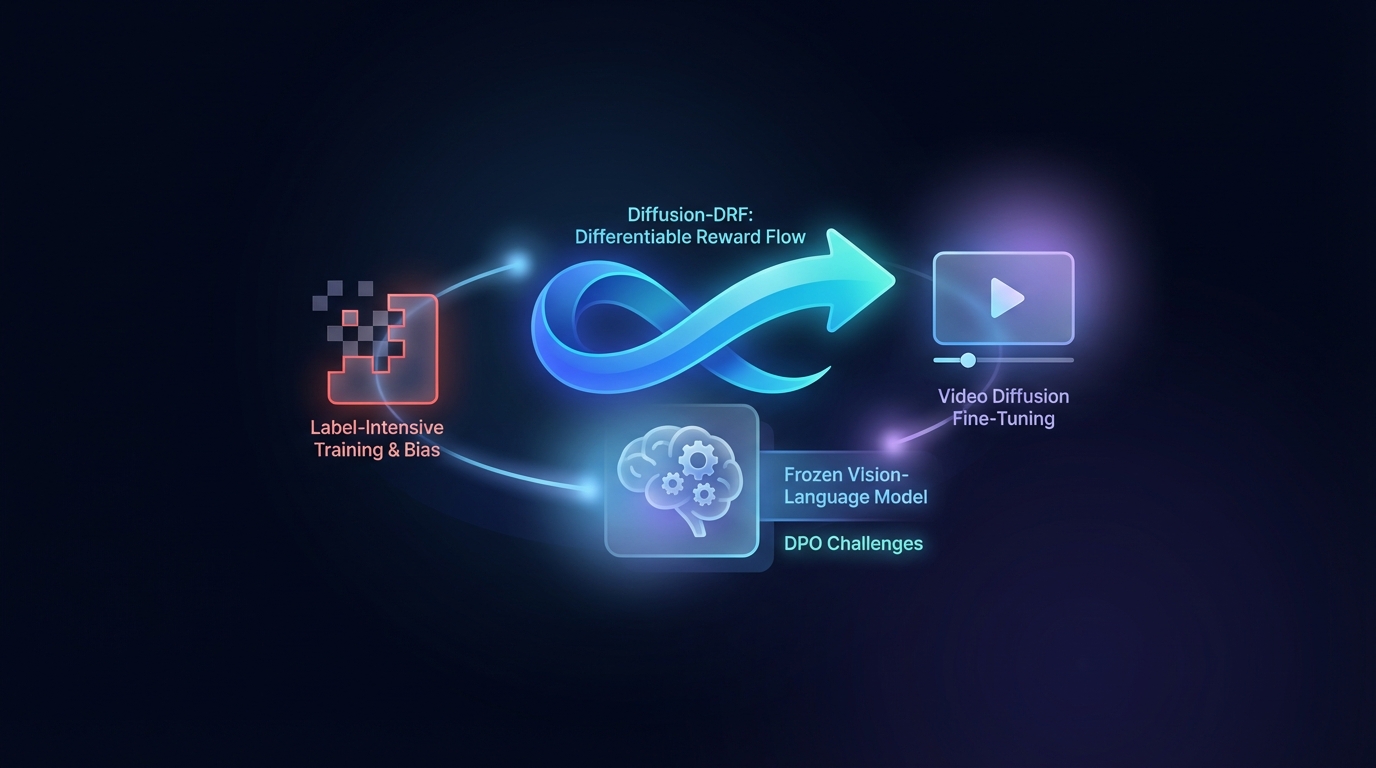
Diffusion-DRF: Дифференцируемый поток вознаграждения для тонкой настройки диффузионного видео
Оптимизация преференций с помощью прямого подхода (DPO) улучшает генерацию видео из текста, но сталкивается с проблемами, связанными с обучением, требующим большого объема меток, и предвзятостью. Предложенный метод Diffusion-DRF использует замороженную модель «Визуальный-языковой» как дифференцируемый критик, что позволяет эффективно передавать обратную связь через модели диффузии видео. Этот подход повышает качество видео и семантическое соответствие, одновременно снижая проблемы с манипуляцией наградами. Кроме того, он адаптируется к другим задачам на основе диффузии без необходимости в дополнительных моделях наград.
arXiv