Мультирегиональный синтетический набор радиологических отчетов Multi-RADS и сравнительное тестирование 41 открытых и проприетарных языковых моделей
Изображение создано Gemini AI
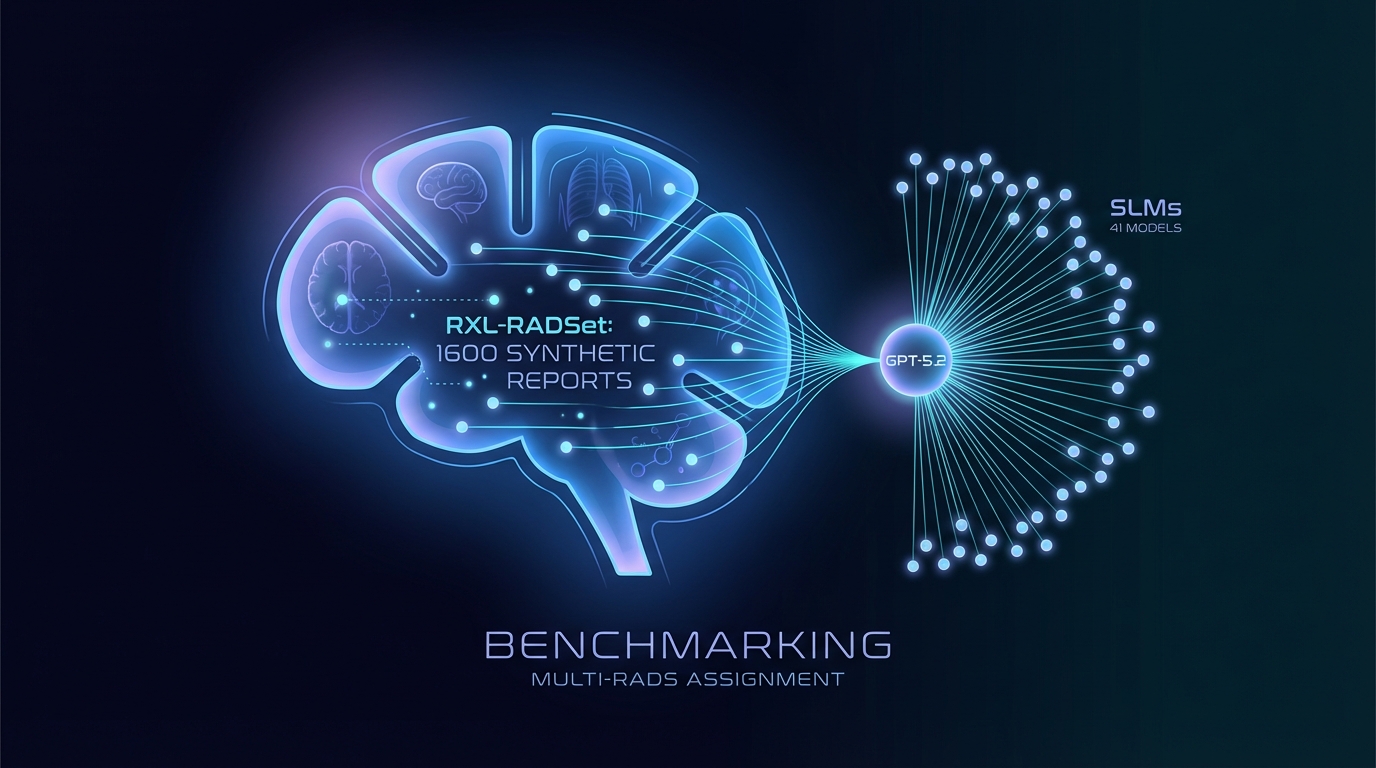
Исследователи разработали RXL-RADSet, набор эталонных данных, состоящий из 1,600 синтетических радиологических отчетов, с целью улучшения автоматической классификации RADS. В рамках исследования была проведена сравнение 41 малой языковой модели (SLM) с GPT-5.2 по критериям точности и валидности. GPT-5.2 достиг 99.8% валидности и 81.1% точности, что превзошло результаты SLM, которые показали 96.8% валидности и 61.1% точности. Производительность улучшалась с увеличением размера модели и использованием направленных подсказок, однако остаются сложности с более сложными структурами RADS.
Выпущен набор данных Multi-RADS для оценки языковых моделей в радиологии
Запущен новый набор данных, направленный на улучшение коммуникации рисков в радиологии, который включает в себя эталон синтетических радиологических отчетов по нескольким системам отчетности и данных (RADS). Известный как RXL-RADSet, он включает 1,600 синтетических отчетов, проверенных радиологами, и предназначен для оценки производительности различных языковых моделей в автоматическом назначении RADS.
Оценка производительности языковых моделей
В исследовании была оценена производительность 41 квантизированной небольшой языковой модели (SLMs) с количеством параметров от 0.135 до 32 миллиардов, наряду с проприетарной моделью GPT-5.2. Основными метриками для оценки были валидность и точность назначений RADS.
Результаты показали, что GPT-5.2 достигла 99.8% валидности и 81.1% точности по 1,600 предсказаниям. В то время как агрегированные SLMs продемонстрировали валидность 96.8% и точность 61.1% из общего числа 65,600 предсказаний. Наилучшие SLMs в диапазоне от 20 до 32 миллиардов параметров приблизились к 99% валидности и достигли средней и высокой точности на уровне 70%.
Анализ выявил тенденцию к улучшению производительности с увеличением размера модели, особенно отмечая точку перегиба между моделями с менее чем 1 миллиардом параметров и теми, у которых 10 миллиардов и более. Однако сложность фреймворков RADS значительно повлияла на производительность, с более высокой сложностью, приводящей к проблемам с классификацией, а не к недействительным результатам.
Улучшенное руководство при запросах повысило как валидность, так и точность, при этом валидные показатели достигли 99.2% по сравнению с 96.7% при нулевом запросе.
Связанные темы:
📰 Первоисточник: https://arxiv.org/abs/2601.03232v1
Все права и авторство принадлежат первоначальному издателю.