Diffusion-DRF: Дифференцируемый поток вознаграждения для тонкой настройки диффузионного видео
Изображение создано Gemini AI
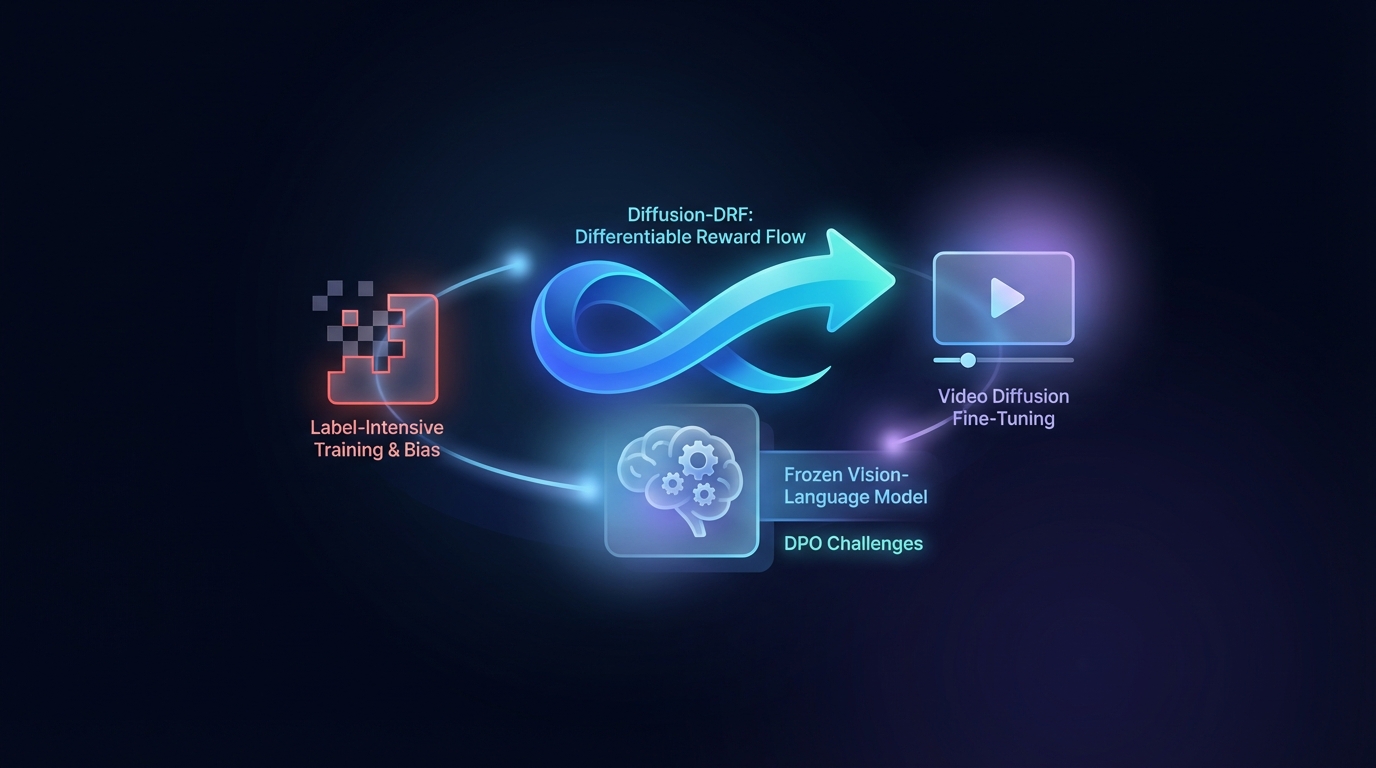
Оптимизация преференций с помощью прямого подхода (DPO) улучшает генерацию видео из текста, но сталкивается с проблемами, связанными с обучением, требующим большого объема меток, и предвзятостью. Предложенный метод Diffusion-DRF использует замороженную модель «Визуальный-языковой» как дифференцируемый критик, что позволяет эффективно передавать обратную связь через модели диффузии видео. Этот подход повышает качество видео и семантическое соответствие, одновременно снижая проблемы с манипуляцией наградами. Кроме того, он адаптируется к другим задачам на основе диффузии без необходимости в дополнительных моделях наград.
Diffusion-DRF: Прорыв в тонкой настройке видеодиффузии
Исследователи представили Diffusion-DRF, новый метод тонкой настройки моделей видеодиффузии, который улучшает качество видео и семантическое соответствие. Этот подход использует замороженную модель "Зрение-Язык" (VLM) в качестве критика без необходимости в обучении, что является значительным шагом вперед по сравнению с существующими методами.
Diffusion-DRF решает общие проблемы традиционной генерации "Текст-в-Видео" (T2V), интегрируя обратную связь от VLM непосредственно в цепочку денойзинга диффузии. Этот метод позволяет проводить обратное распространение обратной связи от VLM, преобразуя ответы на уровне логитов в градиенты, учитывающие токены, что облегчает оптимизацию и эффективно снижает проблемы, связанные с манипуляцией наградами и коллапсом модели.
Примечательно, что Diffusion-DRF является независимым от модели, применимым к различным задачам генерации на основе диффузии, выходящим за пределы генерации T2V, что делает его ценным инструментом для будущих достижений в области генерации видео.
Связанные темы:
📰 Первоисточник: https://arxiv.org/abs/2601.04153v1
Все права и авторство принадлежат первоначальному издателю.