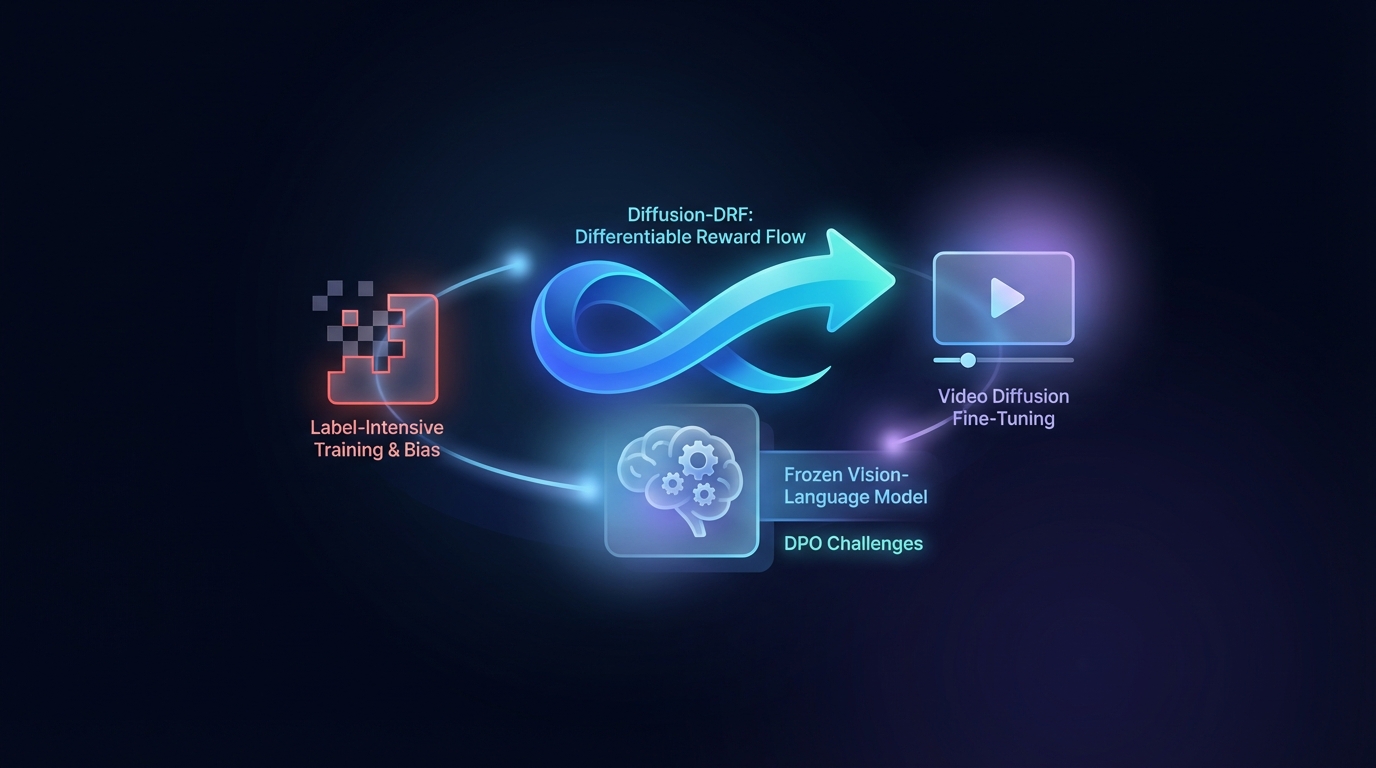
Diffusion-DRF : Flux de Récompense Différentiable pour le Finition de Diffusion Vidéo
L'Optimisation de Préférences Directes (DPO) améliore la génération de vidéos à partir de textes, mais rencontre des défis liés à un entraînement intensif en étiquettes et aux biais. La méthode Diffusion-DRF proposée utilise un Modèle Vision-Langage figé comme critique différentiable, permettant ainsi une rétropropagation efficace des retours d'information à travers les modèles de diffusion vidéo. Cette approche améliore la qualité des vidéos et leur alignement sémantique tout en réduisant les problèmes de manipulation des récompenses, et elle est adaptable à d'autres tâches basées sur la diffusion sans nécessiter de modèles de récompense supplémentaires.
arXiv