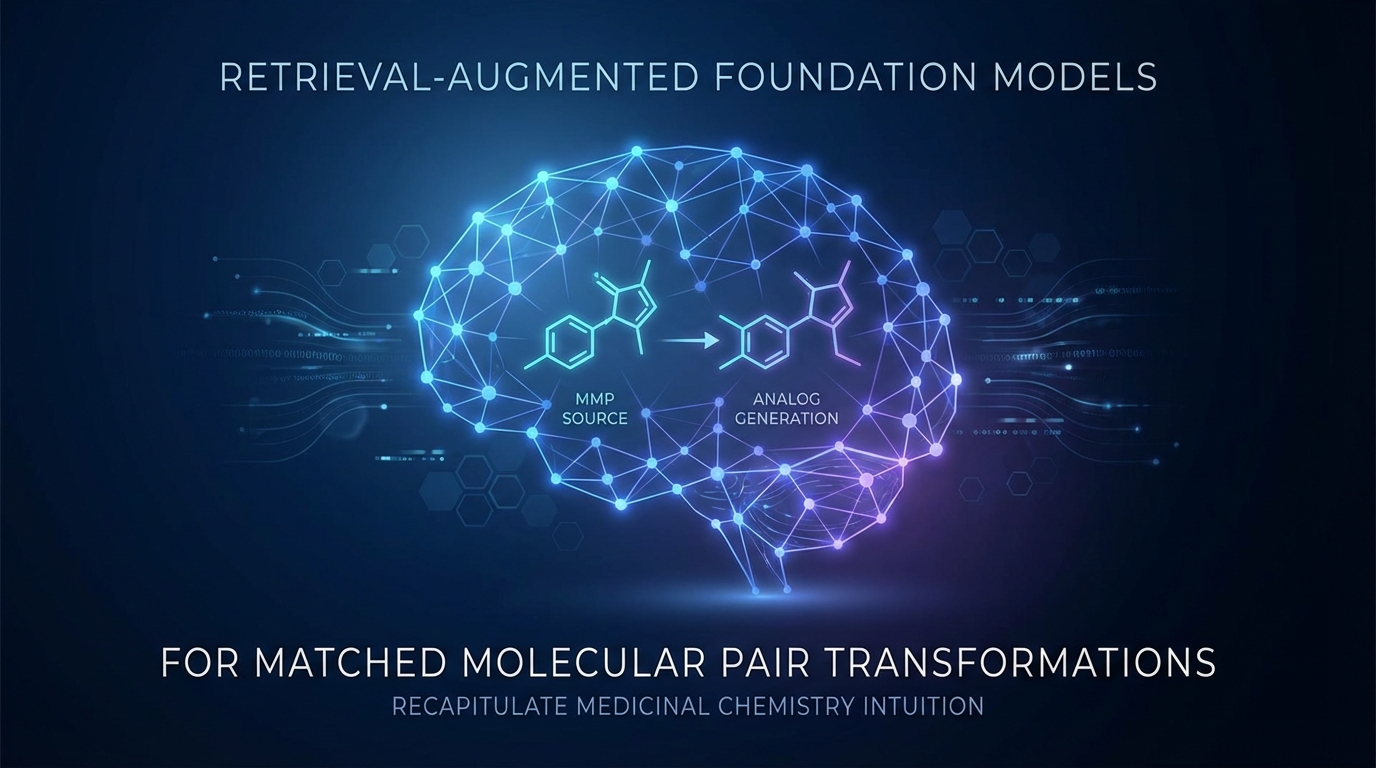
Modèles de fond augmentés par récupération pour les transformations de paires moléculaires appariées afin de recapturer l'intuition en chimie médicinale
Des chercheurs ont mis au point un nouveau modèle de base pour la génération d'analogues chimiques à partir de paires moléculaires appariées (MMP). Ce modèle permet de créer une diversité de variables en fonction de schémas de transformation définis par l'utilisateur, améliorant ainsi le contrôle sur le processus. Baptisée MMPT-RAG, cette méthode intègre des références externes pour renforcer la pertinence contextuelle. Les expériences montrent des avancées significatives en matière de diversité et de nouveauté des composés générés, faisant de cet outil un atout précieux pour la chimie médicinale dans le cadre de la découverte de médicaments.
arXiv