Multi-RADS合成放射学报告数据集及41种开放权重与专有语言模型的对比基准测试
Gemini AI生成的图像
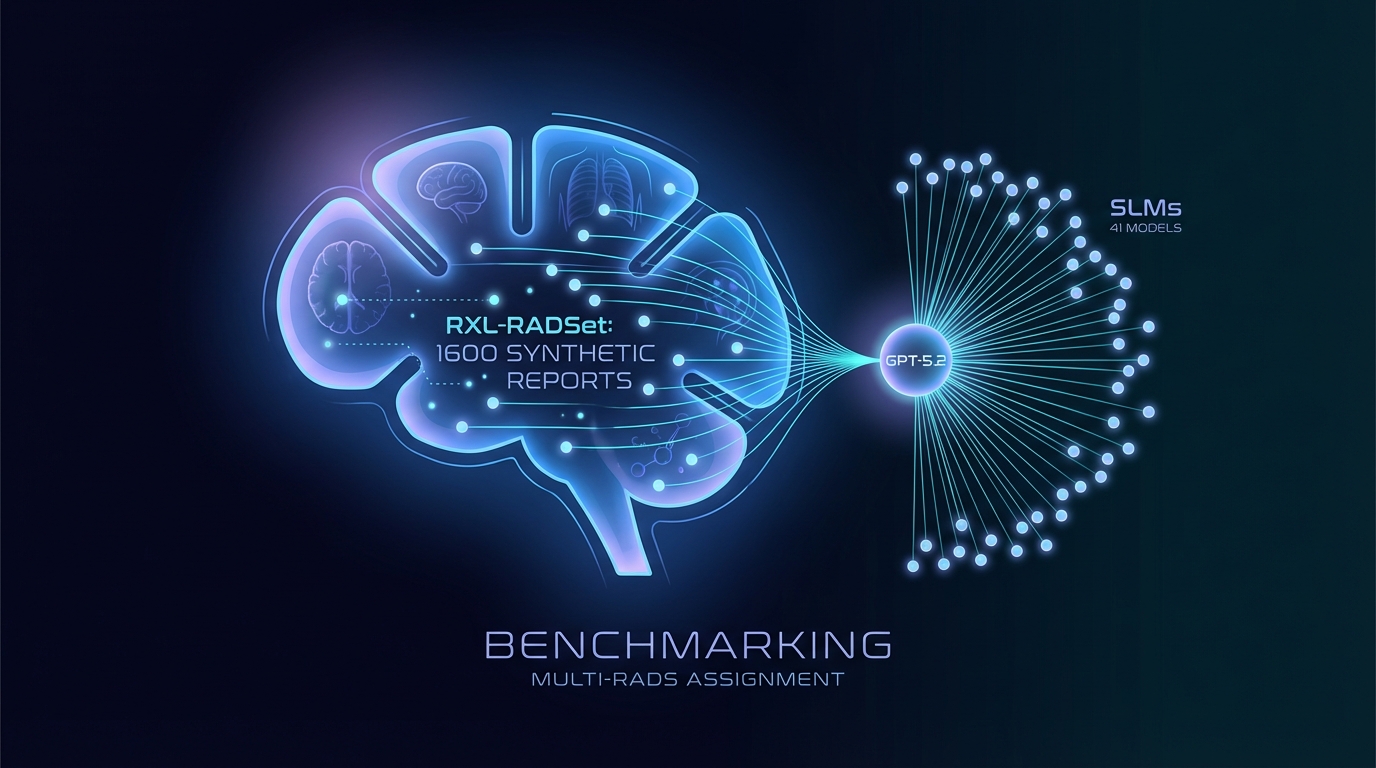
研究人员开发了RXL-RADSet,这是一个包含1,600份合成放射学报告的基准数据集,旨在提高自动化放射学诊断系统(RADS)的分配能力。该研究将41种小型语言模型(SLMs)与GPT-5.2进行了比较,以评估其准确性和有效性。结果显示,GPT-5.2的有效性达到了99.8%,准确性为81.1%,明显优于小型语言模型,这些模型的有效性为96.8%,准确性仅为61.1%。随着模型规模的扩大和引导提示的使用,性能有所提升,但在处理复杂的RADS框架时仍然面临挑战。
针对放射学语言模型发布的多RADS基准数据集
一个旨在增强放射学风险沟通的新数据集已被推出,包含多个报告和数据系统(RADS)下的合成放射学报告基准。该数据集被称为RXL-RADSet,包含1,600份经过放射科医生验证的合成报告,旨在评估各种语言模型在自动RADS分配中的性能。
语言模型的性能评估
该研究评估了41个量化的小型语言模型(SLMs),其参数规模从1.35亿到320亿不等,同时也评价了专有模型GPT-5.2。评估的主要指标是RADS分配的有效性和准确性。
结果显示,GPT-5.2在1,600次预测中实现了99.8%的有效性和81.1%的准确性。相比之下,汇总的SLMs在总共65,600次预测中产生了96.8%的有效性和61.1%的准确性。参数范围在20亿到32亿之间的表现最佳的SLMs接近99%的有效性,且准确率达到了中高70%左右。
分析显示,性能随着模型规模的增加而改善,特别是在参数少于10亿的模型与参数在100亿及以上的模型之间,存在一个拐点。然而,RADS框架的复杂性显著影响了性能,更高的复杂性导致分类挑战而不是无效输出。
指导性提示增强了有效性和准确性,有效性分数达到了99.2%,相比之下,零样本提示的有效性为96.7%。
相关主题:
📰 原始来源: https://arxiv.org/abs/2601.03232v1
所有权利和署名均属于原出版商。