Diffusion-DRF:用于视频扩散微调的可微分奖励流
Gemini AI生成的图像
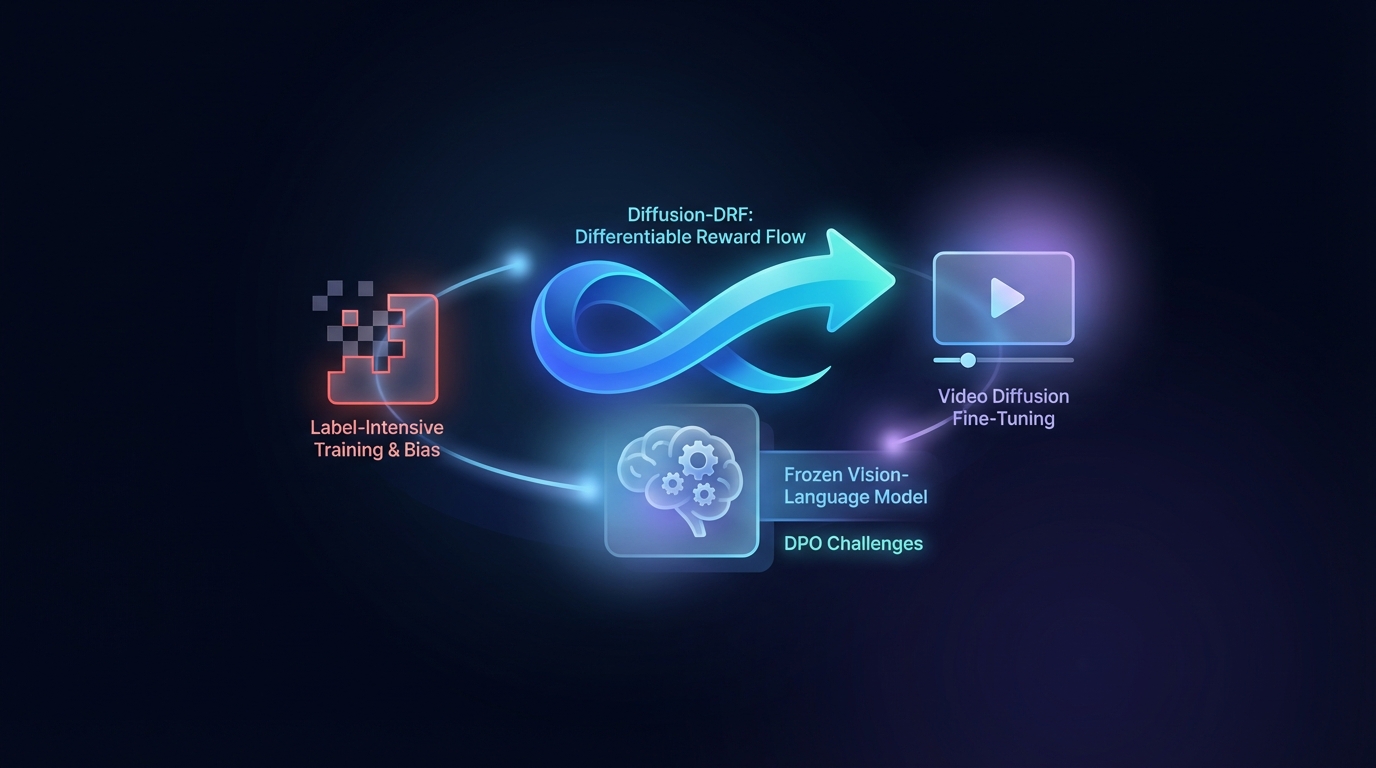
直接偏好优化(DPO)在文本生成视频方面有所提升,但也面临着标签密集型训练和偏见等挑战。提出的扩散-差异反馈(Diffusion-DRF)方法利用一个冻结的视觉-语言模型作为可微分的评判器,使得通过视频扩散模型有效地反向传播反馈成为可能。这种方法不仅提高了视频质量和语义一致性,还减少了奖励操控问题,同时能够适应其他基于扩散的任务,而无需额外的奖励模型。
Diffusion-DRF:视频扩散微调的突破性进展
研究人员推出了Diffusion-DRF,这是一种新颖的视频扩散模型微调方法,能够提升视频质量和语义对齐。这种方法利用一个冻结的视觉语言模型(VLM)作为无训练的评论者,标志着对现有方法的重大进步。
Diffusion-DRF通过将VLM的反馈直接集成到扩散去噪链中,解决了传统文本到视频(T2V)生成中的常见挑战。这种方法允许VLM反馈的反向传播,将logit级别的响应转换为考虑到标记的梯度,从而促进优化,有效缓解了与奖励黑客行为和模型崩溃相关的问题。
值得注意的是,Diffusion-DRF是与模型无关的,适用于多种基于扩散的生成任务,超越了T2V生成,使其成为未来视频生成进展中的宝贵工具。
相关主题:
Diffusion-DRF可微分奖励流文本到视频生成视觉-语言模型奖励黑客行为
📰 原始来源: https://arxiv.org/abs/2601.04153v1
所有权利和署名均属于原出版商。