视频扩散中的因果性与去噪分离
Gemini AI生成的图像
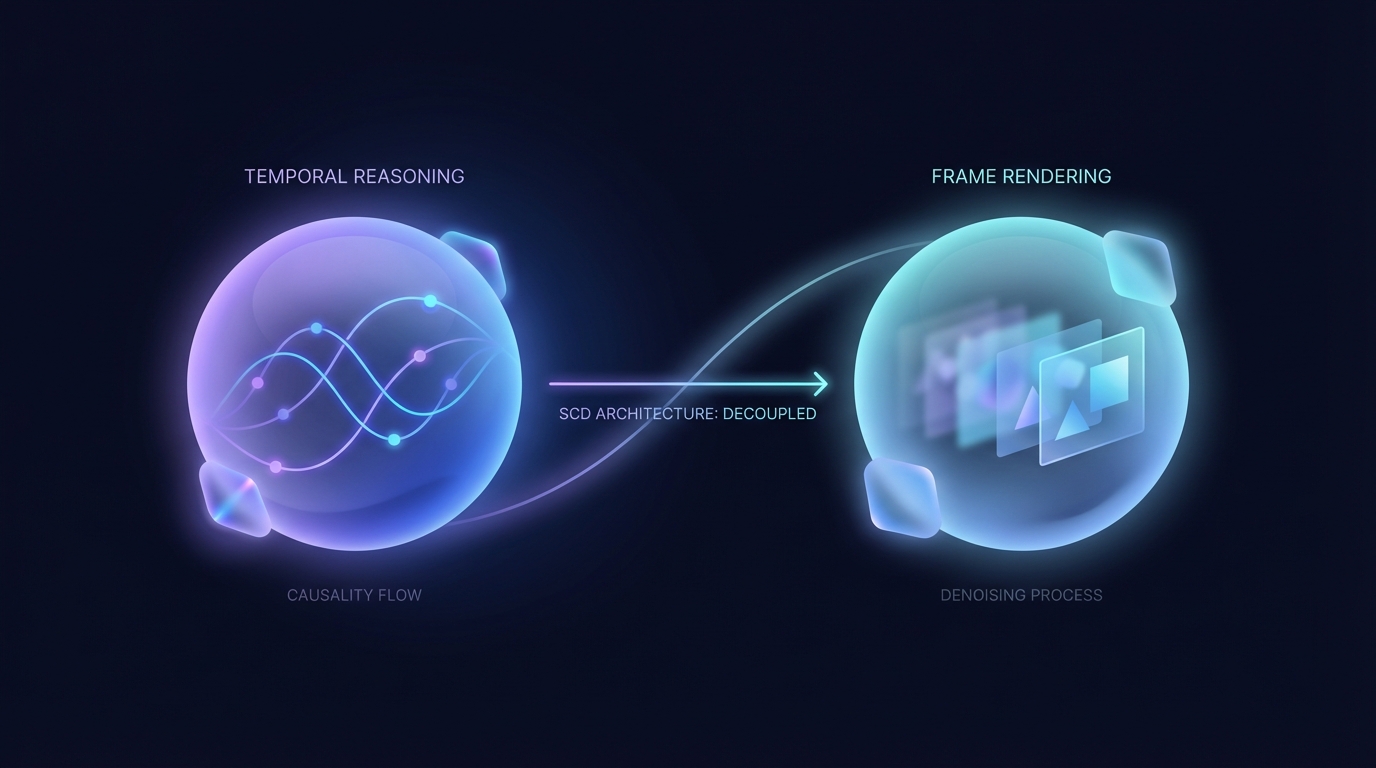
一种新架构——可分离因果扩散(Separable Causal Diffusion,简称SCD)已被开发出来,以增强用于视频生成的因果扩散模型。通过将时间推理与多步帧渲染解耦,SCD提高了效率,实现了更高的处理能力和更低的延迟。实验结果表明,它的质量与现有模型相当或更优,成为生成过程中的一项有前景的创新。
视频扩散中的因果关系与去噪过程分离
最近的一项研究揭示了视频扩散模型中的因果推理可以与去噪过程明显分离。研究人员证明,将因果注意力与迭代去噪步骤解耦可以提高效率和输出质量。
论文通过对自回归视频扩散器的检查,确定了两个重要发现。早期层在不同的去噪步骤中生成高度相似的特征,导致冗余计算。更深层则表现出稀疏的跨帧注意力,更加关注于单个帧的渲染。
作为回应,研究人员推出了一种新的架构,称为可分离因果扩散(SCD)。该模型采用因果变换器编码器来处理逐帧的时间推理,同时利用轻量级的扩散解码器进行渲染。这种分离增强了性能指标。
在各种基准测试中的实验表明,SCD不仅匹配现有因果扩散模型的生成质量,且往往超越,显著提高了吞吐量和每帧延迟。
相关主题:
因果关系视频扩散去噪可分离因果扩散时间推理
📰 原始来源: https://arxiv.org/abs/2602.10095v1
所有权利和署名均属于原出版商。