A Causalidade em Difusores de Vídeo é Separável da Redução de Ruído
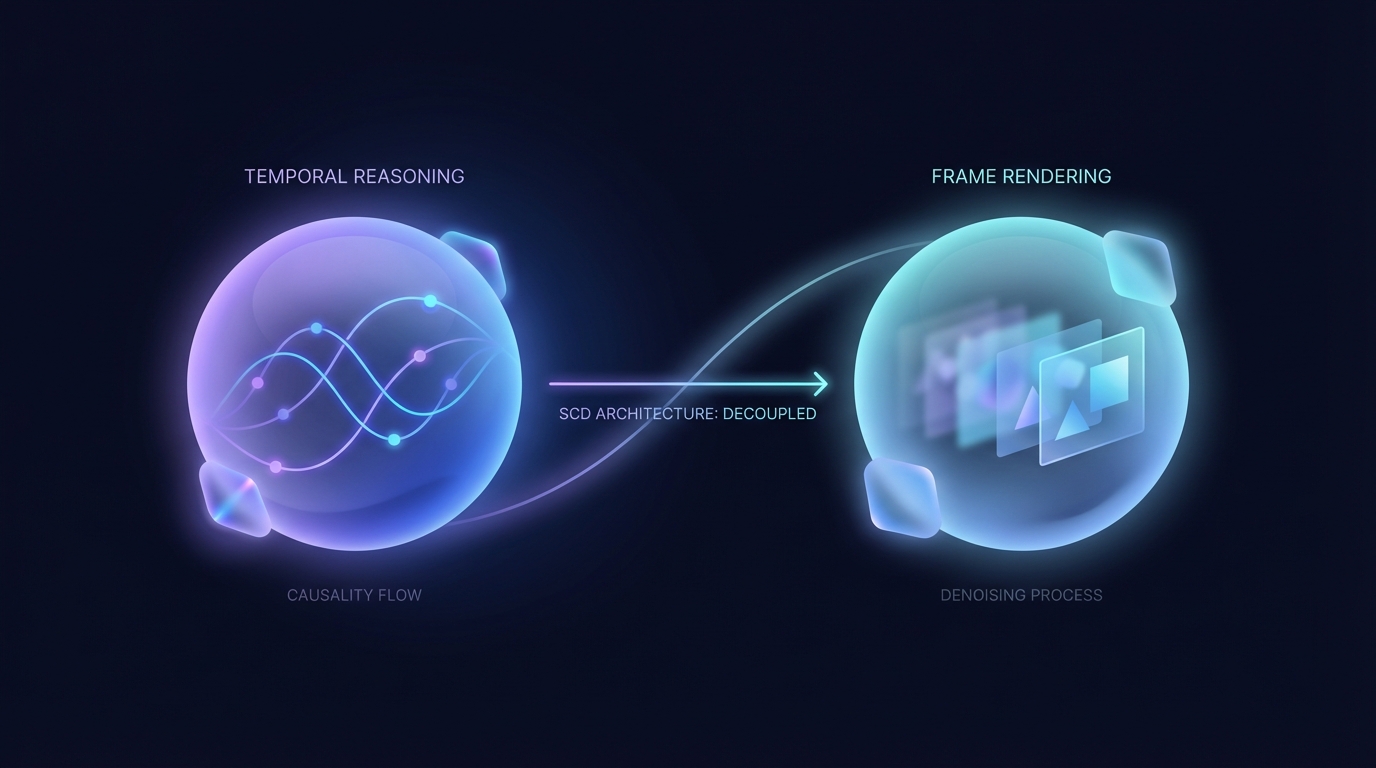
Imagem gerada por Gemini AI
Uma nova arquitetura, chamada Difusão Causal Separável (SCD), foi desenvolvida para aprimorar os modelos de difusão causal utilizados na geração de vídeos. Ao desacoplar o raciocínio temporal da renderização de múltiplos quadros, a SCD melhora a eficiência, alcançando maior taxa de transferência e reduzindo a latência. Experimentos demonstram que sua qualidade é igual ou superior à dos modelos existentes, posicionando-a como uma inovação promissora nos processos generativos.
Causalidade em Difusores de Vídeo Separada da Remoção de Ruído
Um estudo recente revela que o raciocínio causal em modelos de difusão de vídeo pode ser claramente separado do processo de remoção de ruído. Pesquisadores demonstraram que desacoplar a atenção causal dos passos iterativos de remoção de ruído pode melhorar a eficiência e a qualidade do resultado.
O artigo identifica duas descobertas significativas através da análise de difusores de vídeo autorregressivos. As camadas iniciais geram características altamente semelhantes em diferentes passos de remoção de ruído, levando a cálculos redundantes. Camadas mais profundas exibem atenção esparsa entre quadros, focando mais na renderização dentro de quadros individuais.
Em resposta, os pesquisadores introduziram uma nova arquitetura chamada Difusão Causal Separável (DCS). Este modelo emprega um codificador transformer causal para lidar com o raciocínio temporal em uma base de quadro a quadro, enquanto utiliza um decodificador de difusão leve para renderização. Essa separação aprimora as métricas de desempenho.
Experimentos em vários benchmarks indicam que a DCS não apenas iguala, mas muitas vezes supera a qualidade de geração dos modelos de difusão causal existentes, com melhorias significativas na taxa de transferência e na latência por quadro.
Tópicos relacionados:
📰 Fonte original: https://arxiv.org/abs/2602.10095v1
Todos os direitos e créditos pertencem ao editor original.