Embelezamientos Densos y Contextuales Preentrenados por Difusión
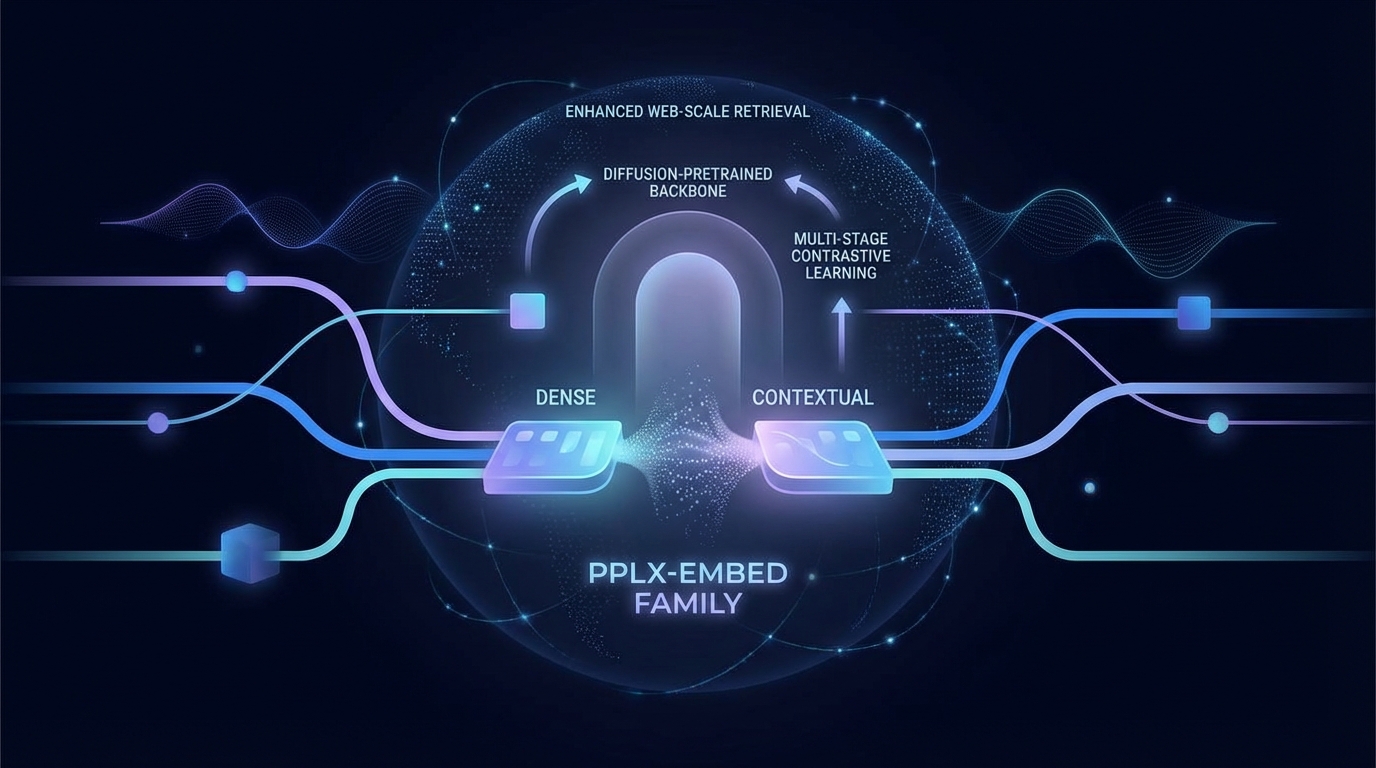
Imagen generada por Gemini AI
La nueva familia de modelos de incrustación multilingüe pplx-embed utiliza un aprendizaje contrastivo de múltiples etapas sobre una arquitectura preentrenada mediante difusión, lo que mejora la recuperación a escala web. Se han lanzado dos variantes: pplx-embed-v1 para tareas estándar y pplx-embed-context-v1 para incrustaciones contextuales. Esta última destaca en el benchmark ConTEB, mientras que ambos modelos muestran un buen desempeño en varios otros benchmarks de recuperación y evaluaciones internas, lo que indica su fiabilidad para aplicaciones de búsqueda a gran escala.
Nuevos Modelos de Embedding Multilingües Listos para Transformar la Recuperación a Escala Web
Investigadores han presentado pplx-embed, una serie de modelos de embedding multilingües diseñados para mejorar los procesos de recuperación a escala web. Utilizando un enfoque de aprendizaje contrastivo en múltiples etapas sobre un modelo de lenguaje preentrenado por difusión, estos modelos tienen como objetivo capturar de manera eficiente el contexto dentro de pasajes extensos.
Los modelos pplx-embed emplean un mecanismo de atención bidireccional que facilita una comprensión integral del contexto del documento. Se han lanzado dos variantes: pplx-embed-v1, optimizado para tareas de recuperación estándar, y pplx-embed-context-v1, que ofrece embeddings contextualizados que integran un contexto documental más amplio en las representaciones de pasajes individuales.
Aspectos Destacados del Rendimiento
El modelo pplx-embed-v1 ha demostrado un rendimiento competitivo en varios benchmarks prominentes, incluyendo:
- MTEB (Multilingüe, v2)
- MTEB (Código)
- MIRACL
- BERGEN
- ToolRet
Notablemente, el modelo pplx-embed-context-v1 ha logrado resultados récord en el benchmark ConTEB, que evalúa la comprensión contextual.
Aplicaciones en el Mundo Real
Más allá de los benchmarks formales, el modelo pplx-embed-v1 ha mostrado un rendimiento robusto en evaluaciones internas que simulan escenarios de búsqueda del mundo real, evaluando la efectividad en decenas de millones de documentos. Esto subraya su potencial para mejorar la calidad y eficiencia de la recuperación en entornos de producción.
Temas relacionados:
📰 Fuente original: https://arxiv.org/abs/2602.11151v1
Todos los derechos y créditos pertenecen al editor original.