Diffusions-vortrainierte dichte und kontextuelle Einbettungen
Von Gemini AI generiertes Bild
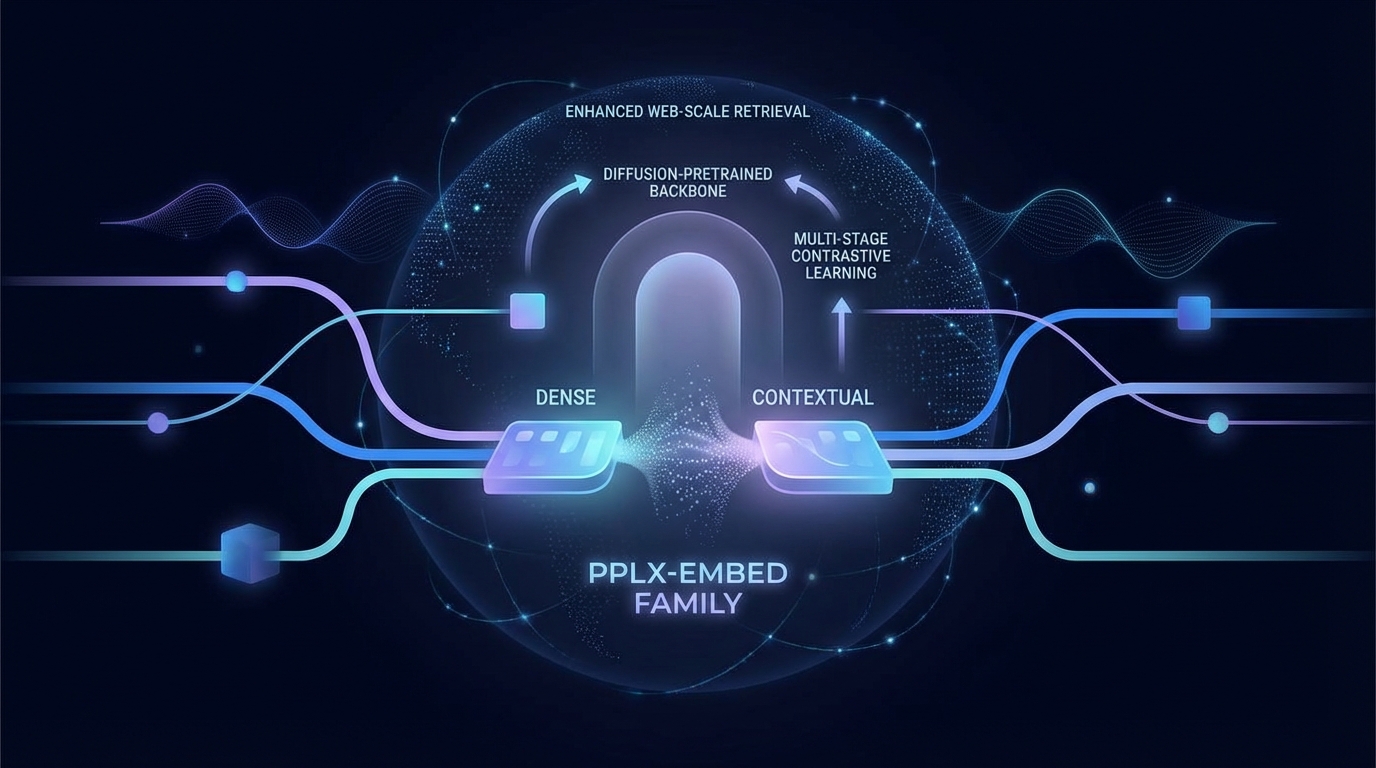
Die neue Modellfamilie pplx-embed für mehrsprachige Einbettungen nutzt ein mehrstufiges kontrastives Lernen auf einem durch Diffusion vortrainierten Backbone, um die Web-Scale-Retrieval-Fähigkeiten zu verbessern. Es wurden zwei Varianten veröffentlicht: pplx-embed-v1 für Standardaufgaben und pplx-embed-context-v1 für kontextuelle Einbettungen. Letztere glänzt im ConTEB-Benchmark, während beide Modelle auch in mehreren anderen Retrieval-Benchmarks und internen Bewertungen gute Ergebnisse erzielen. Dies weist auf ihre Zuverlässigkeit für großangelegte Suchanwendungen hin.
Neue mehrsprachige Einbettungsmodelle sollen die Web-Skalierung abrufen transformieren
Forscher haben pplx-embed enthüllt, eine Reihe von mehrsprachigen Einbettungsmodellen, die darauf ausgelegt sind, die Web-Skalierung Abrufprozesse zu verbessern. Mithilfe eines mehrstufigen kontrastiven Lernansatzes auf einem diffusions-vortrainierten Sprachmodell zielen diese Modelle darauf ab, den Kontext innerhalb langer Passagen effizient zu erfassen.
Die pplx-embed Modelle verwenden einen bidirektionalen Aufmerksamkeitsmechanismus, der ein umfassendes Verständnis des Dokumentkontexts ermöglicht. Zwei Varianten wurden veröffentlicht: pplx-embed-v1, optimiert für Standardabrufaufgaben, und pplx-embed-context-v1, das kontextualisierte Einbettungen bietet, die einen breiteren Dokumentkontext in die Repräsentationen einzelner Passagen integrieren.
Leistungsmerkmale
Das pplx-embed-v1 Modell hat eine wettbewerbsfähige Leistung über mehrere bedeutende Benchmarks hinweg gezeigt, darunter:
- MTEB (Multilingual, v2)
- MTEB (Code)
- MIRACL
- BERGEN
- ToolRet
Bemerkenswert ist, dass das pplx-embed-context-v1 Modell rekordverdächtige Ergebnisse im ConTEB-Benchmark erzielt hat, der das kontextuelle Verständnis bewertet.
Praktische Anwendungen
Über formale Benchmarks hinaus hat das pplx-embed-v1 Modell in internen Bewertungen, die reale Suchszenarien simulieren, eine robuste Leistung gezeigt und die Effektivität bei der Bewertung von Zehntausenden von Dokumenten untersucht. Dies unterstreicht sein Potenzial zur Verbesserung der Abrufqualität und -effizienz in Produktionsumgebungen.
Verwandte Themen:
📰 Originalquelle: https://arxiv.org/abs/2602.11151v1
Alle Rechte und Urheberrechte liegen beim ursprünglichen Herausgeber.