Diffusion-DRF: Flusso di Ricompensa Differenziabile per il Fine-Tuning della Diffusione Video
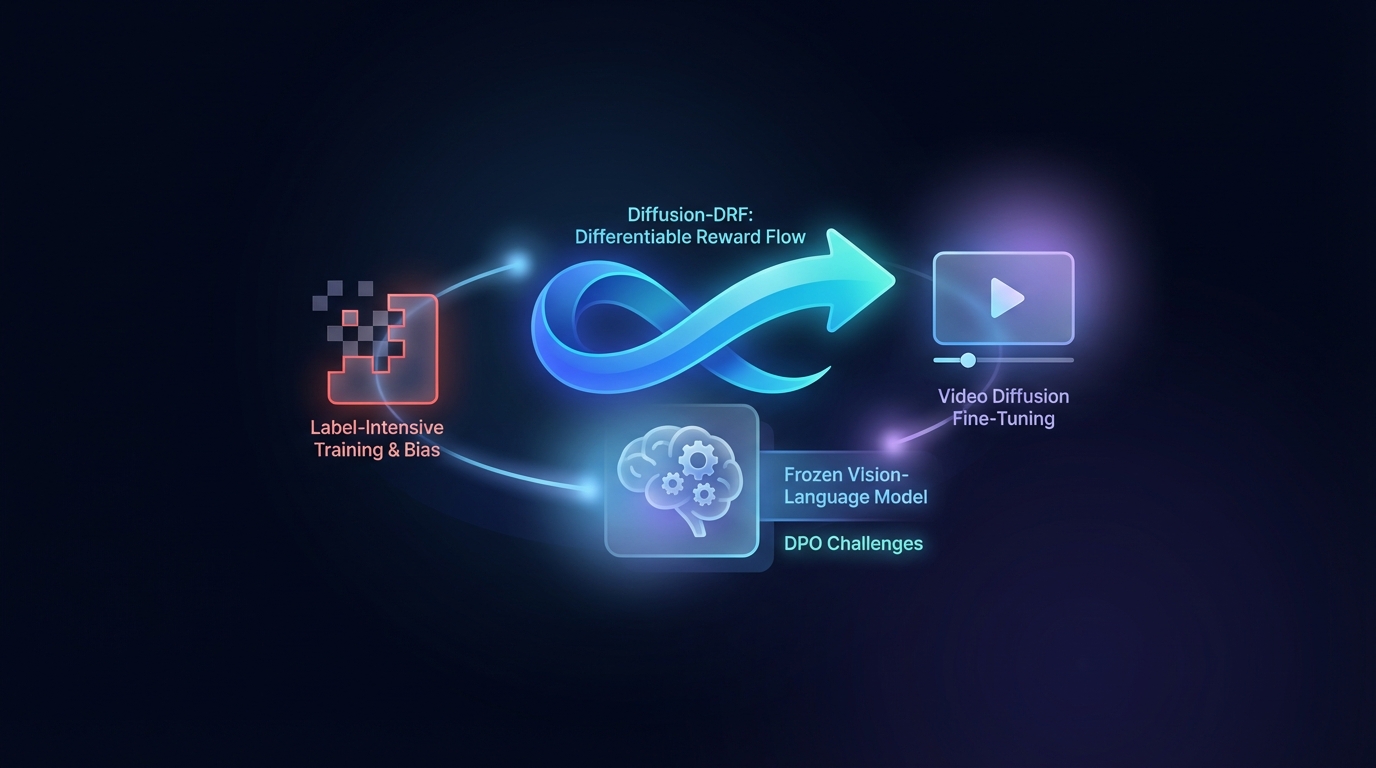
Immagine generata da Gemini AI
L'ottimizzazione diretta delle preferenze (DPO) migliora la generazione di video a partire da testo, ma si trova di fronte a sfide legate a un addestramento intensivo di etichette e ai bias. Il metodo proposto, Diffusion-DRF, utilizza un modello Vision-Language congelato come critico differenziabile, consentendo una retropropagazione efficiente dei feedback attraverso i modelli di diffusione video. Questo approccio migliora la qualità dei video e l'allineamento semantico, riducendo al contempo i problemi legati al "reward hacking". Inoltre, è adattabile ad altri compiti basati sulla diffusione senza la necessità di modelli di ricompensa aggiuntivi.
Diffusion-DRF: Una Riscossa nel Fine-Tuning della Diffusione Video
I ricercatori hanno introdotto Diffusion-DRF, un nuovo metodo per il fine-tuning dei modelli di diffusione video che migliora la qualità video e l'allineamento semantico. Questo approccio sfrutta un Modello Vision-Language (VLM) congelato come critico senza necessità di addestramento, segnando un progresso significativo rispetto ai metodi esistenti.
Diffusion-DRF affronta le sfide comuni nella generazione tradizionale di Testo-in-Video (T2V) integrando il feedback del VLM direttamente nella catena di denoising della diffusione. Questo metodo consente la retropropagazione del feedback del VLM, convertendo le risposte a livello di logit in gradienti consapevoli dei token che facilitano l'ottimizzazione, mitigando efficacemente i problemi legati al reward hacking e al collasso del modello.
È importante notare che Diffusion-DRF è agnostico rispetto ai modelli, applicabile a vari compiti generativi basati sulla diffusione oltre alla generazione T2V, posizionandosi come uno strumento prezioso per i futuri progressi nella generazione video.
Argomenti correlati:
📰 Fonte originale: https://arxiv.org/abs/2601.04153v1
Tutti i diritti e i crediti appartengono all'editore originale.