Dataset di Rapporti Radiologici Sintetici Multi-RADS e Confronto Diretto tra 41 Modelli Linguistici Open-Weight e Proprietari
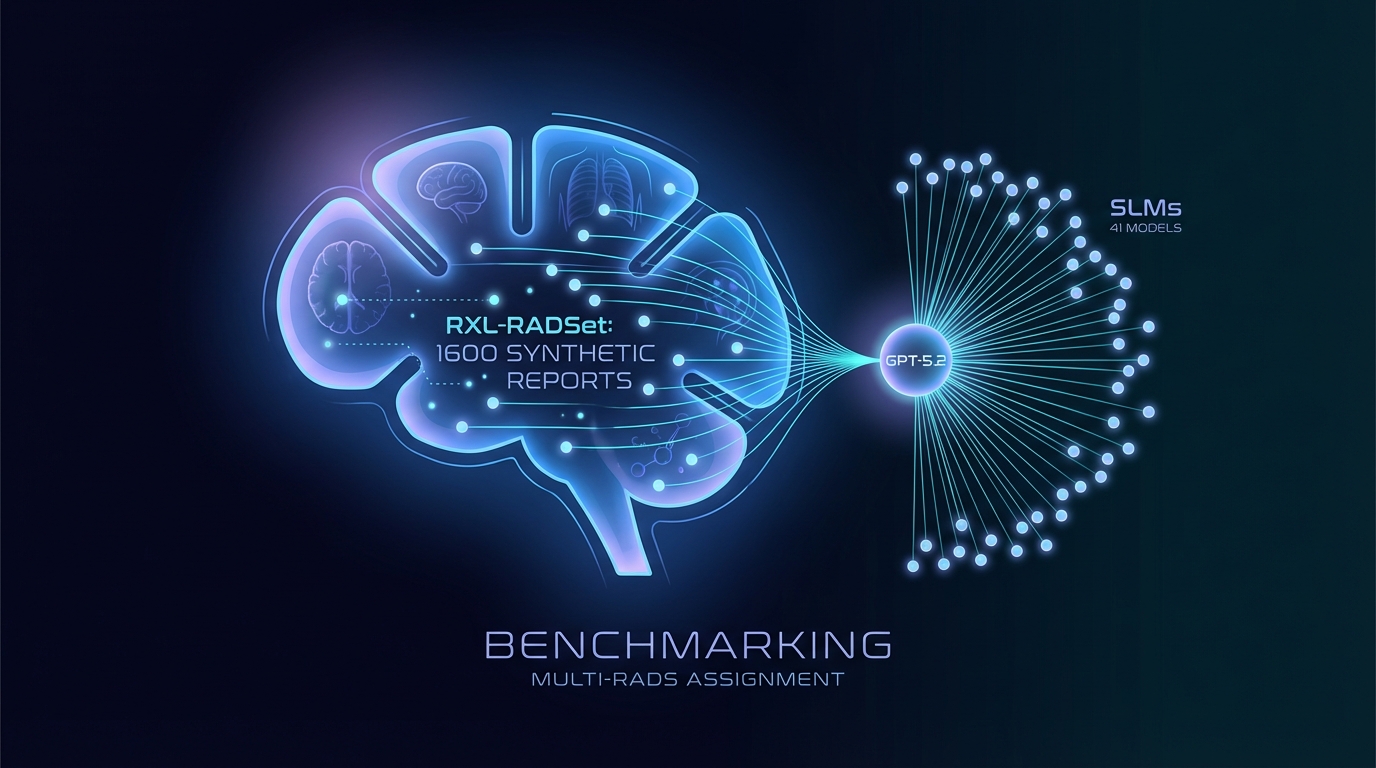
Immagine generata da Gemini AI
I ricercatori hanno sviluppato RXL-RADSet, un benchmark composto da 1.600 rapporti radiologici sintetici, per migliorare l'assegnazione automatizzata dei RADS. Lo studio confronta 41 piccoli modelli linguistici (SLM) con GPT-5.2 in termini di accuratezza e validità. GPT-5.2 ha raggiunto il 99,8% di validità e l'81,1% di accuratezza, superando gli SLM, che hanno mostrato una validità del 96,8% e un'accuratezza del 61,1%. Le performance sono migliorate con l'aumentare delle dimensioni del modello e l'uso di suggerimenti guidati, ma permangono sfide per i framework RADS più complessi.
Dataset di Benchmark Multi-RADS Rilasciato per Modelli Linguistici in Radiologia
È stato lanciato un nuovo dataset volto a migliorare la comunicazione del rischio in radiologia, che presenta un benchmark di report radiologici sintetici attraverso diversi Sistemi di Reporting e Dati (RADS). Conosciuto come RXL-RADSet, include 1.600 report sintetici verificati da radiologi, progettati per valutare le prestazioni di vari modelli linguistici nell'assegnazione automatizzata dei RADS.
Valutazione delle Prestazioni dei Modelli Linguistici
Lo studio ha valutato 41 modelli linguistici piccoli quantizzati (SLMs) con dimensioni dei parametri che variano da 0,135 a 32 miliardi, insieme al modello proprietario GPT-5.2. I principali parametri per la valutazione erano la validità e l'accuratezza delle assegnazioni RADS.
I risultati hanno indicato che GPT-5.2 ha raggiunto una validità del 99,8% e un'accuratezza dell'81,1% su 1.600 previsioni. Al contrario, gli SLMs aggregati hanno prodotto una validità del 96,8% e un'accuratezza del 61,1% su un totale di 65.600 previsioni. I migliori SLMs nella gamma di 20-32 miliardi di parametri si sono avvicinati al 99% di validità e hanno raggiunto tassi di accuratezza tra il 70% e l'80%.
L'analisi ha rivelato una tendenza secondo cui le prestazioni migliorano con l'aumento delle dimensioni del modello, notando in particolare un punto di inflessione tra i modelli con meno di 1 miliardo di parametri e quelli con 10 miliardi o più. Tuttavia, la complessità dei framework RADS ha avuto un impatto significativo sulle prestazioni, con una maggiore complessità che ha portato a sfide di classificazione piuttosto che a output non validi.
Un prompting guidato ha migliorato sia la validità che l'accuratezza, con punteggi di validità che hanno raggiunto il 99,2% rispetto al 96,7% con il prompting zero-shot.
Argomenti correlati:
📰 Fonte originale: https://arxiv.org/abs/2601.03232v1
Tutti i diritti e i crediti appartengono all'editore originale.